 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Visual-Language Alignment of the Q-Former for Visual Reasoning Tasks
Oct 12, 2024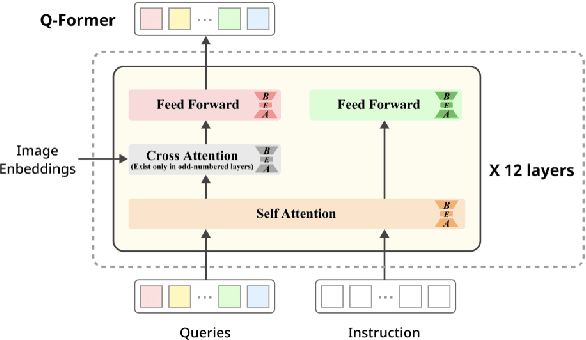
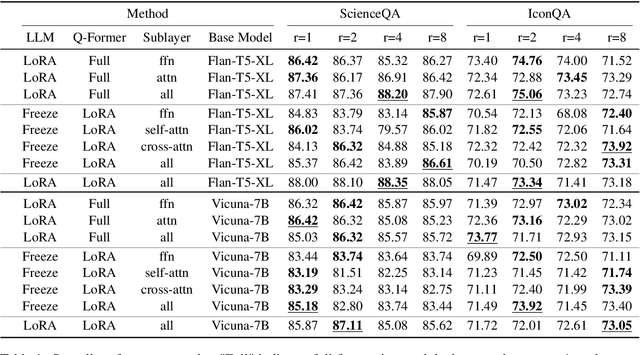
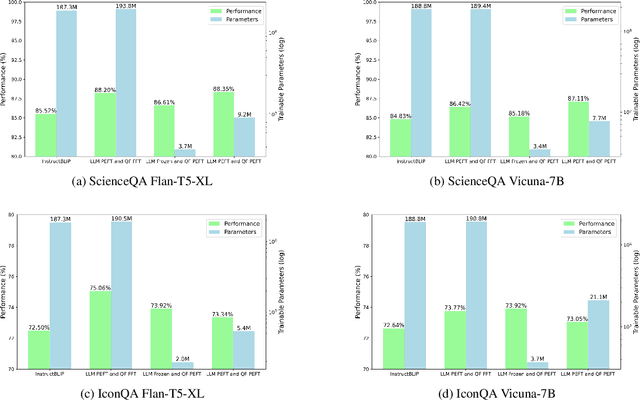
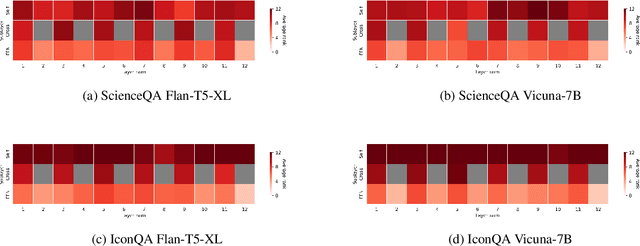
Recent advancements in large language models have demonstrated enhanced capabilities in visual reasoning tasks by employing additional encoders for aligning different modalities. While the Q-Former has been widely used as a general encoder for aligning several modalities including image, video, audio, and 3D with large language models, previous works on its efficient training and the analysis of its individual components have been limited. In this work, we investigate the effectiveness of parameter efficient fine-tuning (PEFT) the Q-Former using InstructBLIP with visual reasoning benchmarks ScienceQA and IconQA. We observe that applying PEFT to the Q-Former achieves comparable performance to full fine-tuning using under 2% of the trainable parameters. Additionally, we employ AdaLoRA for dynamic parameter budget reallocation to examine the relative importance of the Q-Former's sublayers with 4 different benchmarks. Our findings reveal that the self-attention layers are noticeably more important in perceptual visual-language reasoning tasks, and relative importance of FFN layers depends on the complexity of visual-language patterns involved in tasks. The code is available at https://github.com/AttentionX/InstructBLIP_PEFT.
MERLIN: Multimodal Embedding Refinement via LLM-based Iterative Navigation for Text-Video Retrieval-Rerank Pipeline
Jul 17, 2024



The rapid expansion of multimedia content has made accurately retrieving relevant videos from large collections increasingly challenging. Recent advancements in text-video retrieval have focused on cross-modal interactions, large-scale foundation model training, and probabilistic modeling, yet often neglect the crucial user perspective, leading to discrepancies between user queries and the content retrieved. To address this, we introduce MERLIN (Multimodal Embedding Refinement via LLM-based Iterative Navigation), a novel, training-free pipeline that leverages Large Language Models (LLMs) for iterative feedback learning. MERLIN refines query embeddings from a user perspective, enhancing alignment between queries and video content through a dynamic question answering process. Experimental results on datasets like MSR-VTT, MSVD, and ActivityNet demonstrate that MERLIN substantially improves Recall@1, outperforming existing systems and confirming the benefits of integrating LLMs into multimodal retrieval systems for more responsive and context-aware multimedia retrieval.
Contrastive Weighted Learning for Near-Infrared Gaze Estimation
Nov 06, 2022
Appearance-based gaze estimation has been very successful with the use of deep learning. Many following works improved domain generalization for gaze estimation. However, even though there has been much progress in domain generalization for gaze estimation, most of the recent work have been focused on cross-dataset performance -- accounting for different distributions in illuminations, head pose, and lighting. Although improving gaze estimation in different distributions of RGB images is important, near-infrared image based gaze estimation is also critical for gaze estimation in dark settings. Also there are inherent limitations relying solely on supervised learning for regression tasks. This paper contributes to solving these problems and proposes GazeCWL, a novel framework for gaze estimation with near-infrared images using contrastive learning. This leverages adversarial attack techniques for data augmentation and a novel contrastive loss function specifically for regression tasks that effectively clusters the features of different samples in the latent space. Our model outperforms previous domain generalization models in infrared image based gaze estimation and outperforms the baseline by 45.6\% while improving the state-of-the-art by 8.6\%, we demonstrate the efficacy of our method.