 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Answers, Messier Data: Bridging the Gap in Low-Resource Retrieval-Augmented Generation for Domain Expert Systems
Feb 26, 2025RAG has become a key technique for enhancing LLMs by reducing hallucinations, especially in domain expert systems where LLMs may lack sufficient inherent knowledge. However, developing these systems in low-resource settings introduces several challenges: (1) handling heterogeneous data sources, (2) optimizing retrieval phase for trustworthy answers, and (3) evaluating generated answers across diverse aspects. To address these, we introduce a data generation pipeline that transforms raw multi-modal data into structured corpus and Q&A pairs, an advanced re-ranking phase improving retrieval precision, and a reference matching algorithm enhancing answer traceability. Applied to the automotive engineering domain, our system improves factual correctness (+1.94), informativeness (+1.16), and helpfulness (+1.67) over a non-RAG baseline, based on a 1-5 scale by an LLM judge. These results highlight the effectiveness of our approach across distinct aspects, with strong answer grounding and transparency.
Is thermography a viable solution for detecting pressure injuries in dark skin patients?
Nov 15, 2024Pressure injury (PI) detection is challenging, especially in dark skin tones, due to the unreliability of visual inspection. Thermography has been suggested as a viable alternative as temperature differences in the skin can indicate impending tissue damage. Although deep learning models have demonstrated considerable promise toward reliably detecting PI, the existing work fails to evaluate the performance on darker skin tones and varying data collection protocols. In this paper, we introduce a new thermal and optical imaging dataset of 35 participants focused on darker skin tones where temperature differences are induced through cooling and cupping protocols. We vary the image collection process to include different cameras, lighting, patient pose, and camera distance. We compare the performance of a small convolutional neural network (CNN) trained on either the thermal or the optical images on all skin tones. Our preliminary results suggest that thermography-based CNN is robust to data collection protocols for all skin tones.
Expanding Search Space with Diverse Prompting Agents: An Efficient Sampling Approach for LLM Mathematical Reasoning
Oct 13, 2024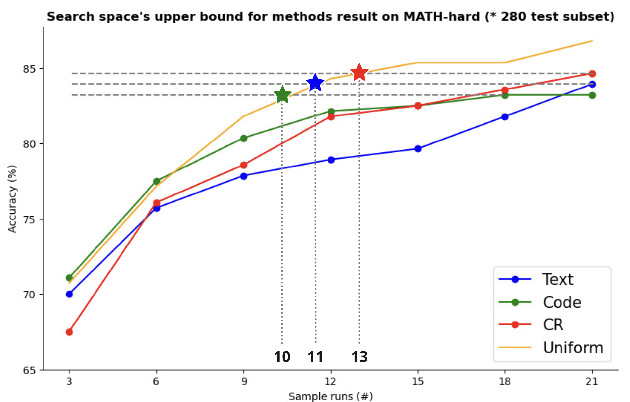
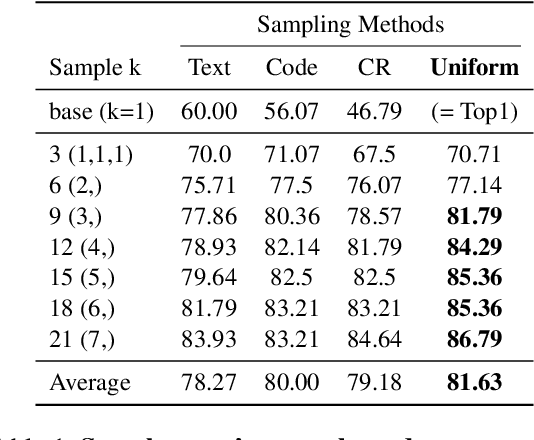
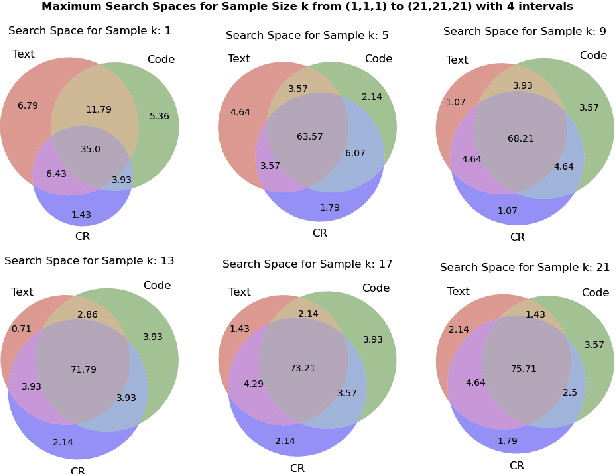
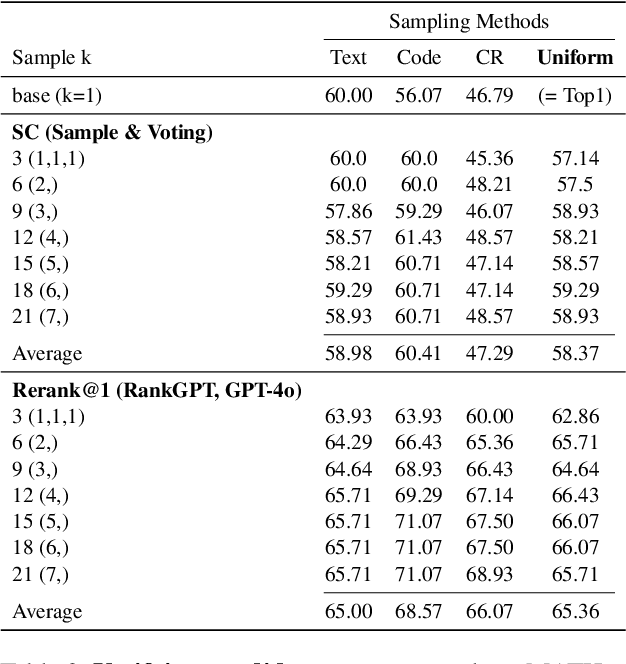
Large Language Models (LLMs) have exhibited remarkable capabilities in many complex tasks including mathematical reasoning. However, traditional approaches heavily rely on ensuring self-consistency within single prompting method, which limits the exploration of diverse problem-solving strategies. This study addresses these limitations by performing an experimental analysis of distinct prompting methods within the domain of mathematical reasoning. Our findings demonstrate that each method explores a distinct search space, and this differentiation becomes more evident with increasing problem complexity. To leverage this phenomenon, we applied efficient sampling process that uniformly combines samples from these diverse methods, which not only expands the maximum search space but achieves higher performance with fewer runs compared to single methods. Especially, within the subset of difficult questions of MATH dataset named MATH-hard, The maximum search space was achieved while utilizing approximately 43% fewer runs than single methods on average. These findings highlight the importance of integrating diverse problem-solving strategies to enhance the reasoning abilities of LLMs.
Towards Efficient Visual-Language Alignment of the Q-Former for Visual Reasoning Tasks
Oct 12, 2024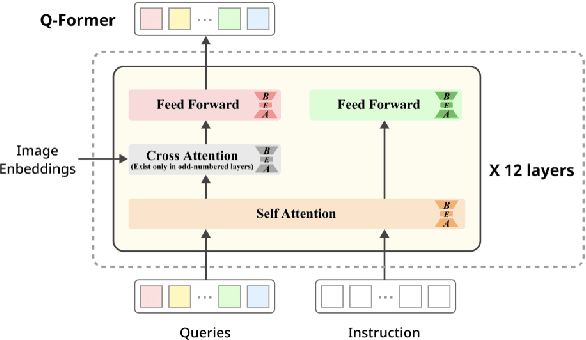
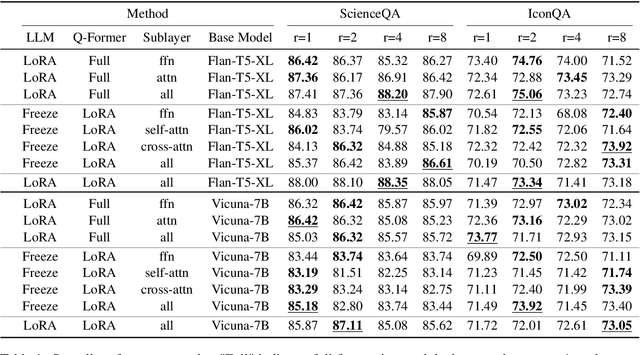
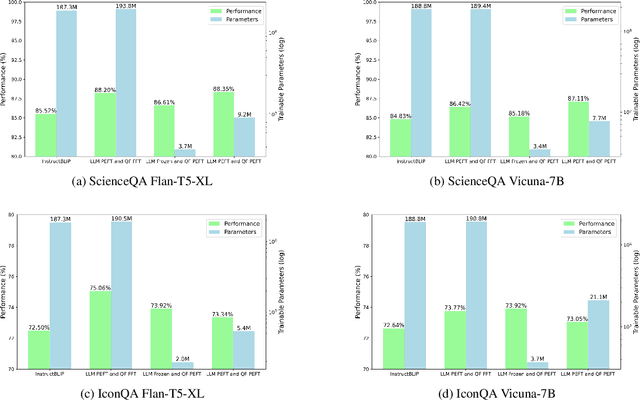
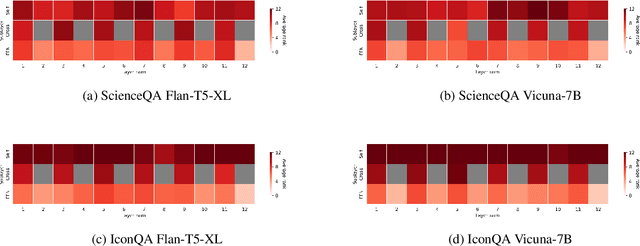
Recent advancements in large language models have demonstrated enhanced capabilities in visual reasoning tasks by employing additional encoders for aligning different modalities. While the Q-Former has been widely used as a general encoder for aligning several modalities including image, video, audio, and 3D with large language models, previous works on its efficient training and the analysis of its individual components have been limited. In this work, we investigate the effectiveness of parameter efficient fine-tuning (PEFT) the Q-Former using InstructBLIP with visual reasoning benchmarks ScienceQA and IconQA. We observe that applying PEFT to the Q-Former achieves comparable performance to full fine-tuning using under 2% of the trainable parameters. Additionally, we employ AdaLoRA for dynamic parameter budget reallocation to examine the relative importance of the Q-Former's sublayers with 4 different benchmarks. Our findings reveal that the self-attention layers are noticeably more important in perceptual visual-language reasoning tasks, and relative importance of FFN layers depends on the complexity of visual-language patterns involved in tasks. The code is available at https://github.com/AttentionX/InstructBLIP_PEFT.