 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpanding Search Space with Diverse Prompting Agents: An Efficient Sampling Approach for LLM Mathematical Reasoning
Oct 13, 2024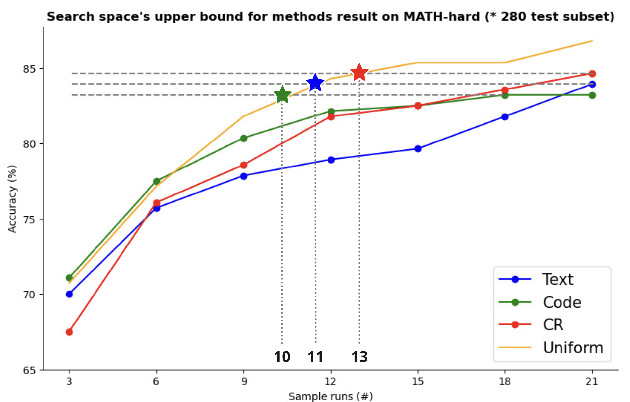
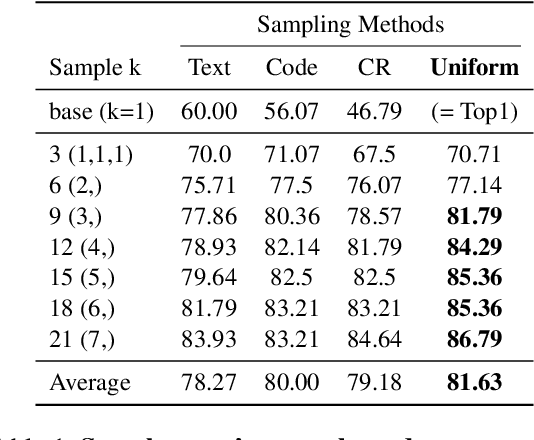
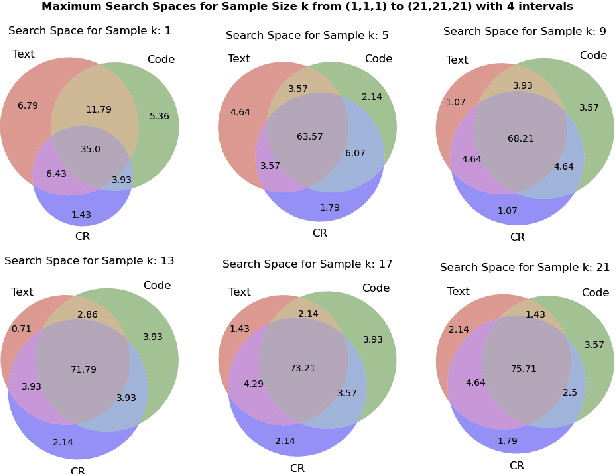
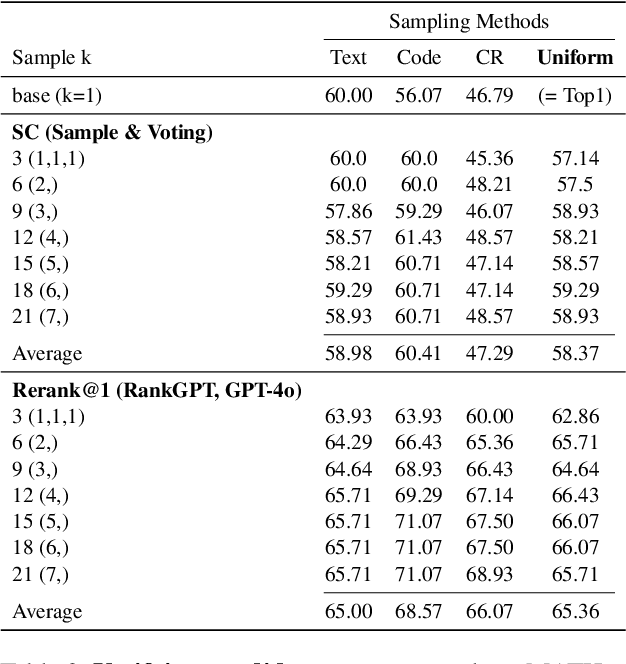
Large Language Models (LLMs) have exhibited remarkable capabilities in many complex tasks including mathematical reasoning. However, traditional approaches heavily rely on ensuring self-consistency within single prompting method, which limits the exploration of diverse problem-solving strategies. This study addresses these limitations by performing an experimental analysis of distinct prompting methods within the domain of mathematical reasoning. Our findings demonstrate that each method explores a distinct search space, and this differentiation becomes more evident with increasing problem complexity. To leverage this phenomenon, we applied efficient sampling process that uniformly combines samples from these diverse methods, which not only expands the maximum search space but achieves higher performance with fewer runs compared to single methods. Especially, within the subset of difficult questions of MATH dataset named MATH-hard, The maximum search space was achieved while utilizing approximately 43% fewer runs than single methods on average. These findings highlight the importance of integrating diverse problem-solving strategies to enhance the reasoning abilities of LLMs.
Advancing 6D Pose Estimation in Augmented Reality -- Overcoming Projection Ambiguity with Uncontrolled Imagery
Mar 20, 2024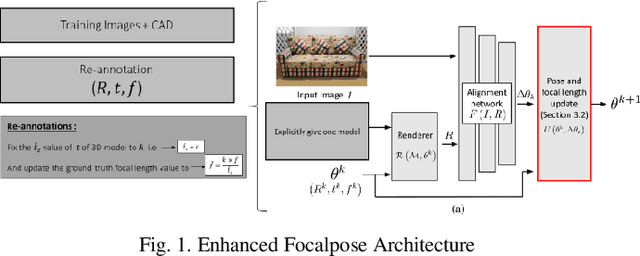

This study addresses the challenge of accurate 6D pose estimation in Augmented Reality (AR), a critical component for seamlessly integrating virtual objects into real-world environments. Our research primarily addresses the difficulty of estimating 6D poses from uncontrolled RGB images, a common scenario in AR applications, which lacks metadata such as focal length. We propose a novel approach that strategically decomposes the estimation of z-axis translation and focal length, leveraging the neural-render and compare strategy inherent in the FocalPose architecture. This methodology not only streamlines the 6D pose estimation process but also significantly enhances the accuracy of 3D object overlaying in AR settings. Our experimental results demonstrate a marked improvement in 6D pose estimation accuracy, with promising applications in manufacturing and robotics. Here, the precise overlay of AR visualizations and the advancement of robotic vision systems stand to benefit substantially from our findings.
One-to-many Approach for Improving Super-Resolution
Jun 22, 2021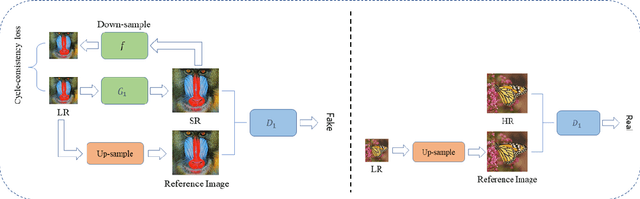
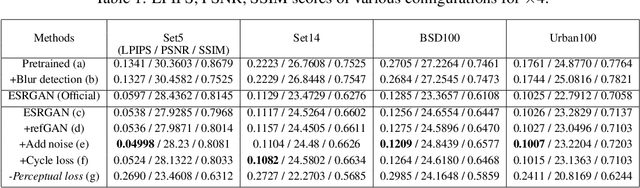
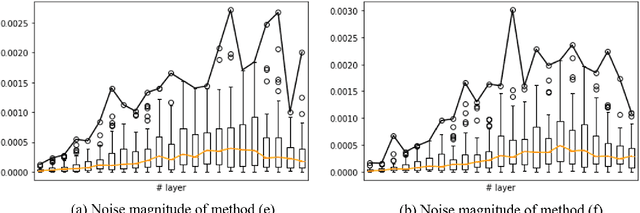
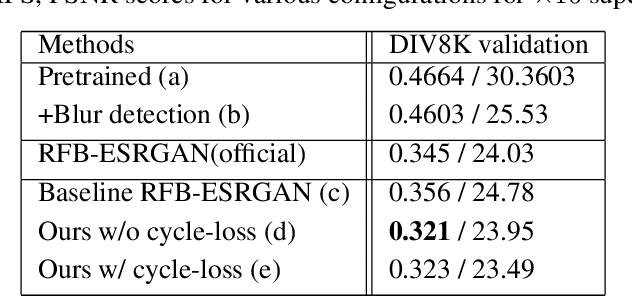
Super-resolution (SR) is a one-to-many task with multiple possible solutions. However, previous works were not concerned about this characteristic. For a one-to-many pipeline, the generator should be able to generate multiple estimates of the reconstruction, and not be penalized for generating similar and equally realistic images. To achieve this, we propose adding weighted pixel-wise noise after every Residual-in-Residual Dense Block (RRDB) to enable the generator to generate various images. We modify the strict content loss to not penalize the stochastic variation in reconstructed images as long as it has consistent content. Additionally, we observe that there are out-of-focus regions in the DIV2K, DIV8K datasets that provide unhelpful guidelines. We filter blurry regions in the training data using the method of [10]. Finally, we modify the discriminator to receive the low-resolution image as a reference image along with the target image to provide better feedback to the generator. Using our proposed methods, we were able to improve the performance of ESRGAN in x4 perceptual SR and achieve the state-of-the-art LPIPS score in x16 perceptual extreme SR.