 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClutt3R-Seg: Sparse-view 3D Instance Segmentation for Language-grounded Grasping in Cluttered Scenes
Feb 12, 2026Reliable 3D instance segmentation is fundamental to language-grounded robotic manipulation. Its critical application lies in cluttered environments, where occlusions, limited viewpoints, and noisy masks degrade perception. To address these challenges, we present Clutt3R-Seg, a zero-shot pipeline for robust 3D instance segmentation for language-grounded grasping in cluttered scenes. Our key idea is to introduce a hierarchical instance tree of semantic cues. Unlike prior approaches that attempt to refine noisy masks, our method leverages them as informative cues: through cross-view grouping and conditional substitution, the tree suppresses over- and under-segmentation, yielding view-consistent masks and robust 3D instances. Each instance is enriched with open-vocabulary semantic embeddings, enabling accurate target selection from natural language instructions. To handle scene changes during multi-stage tasks, we further introduce a consistency-aware update that preserves instance correspondences from only a single post-interaction image, allowing efficient adaptation without rescanning. Clutt3R-Seg is evaluated on both synthetic and real-world datasets, and validated on a real robot. Across all settings, it consistently outperforms state-of-the-art baselines in cluttered and sparse-view scenarios. Even on the most challenging heavy-clutter sequences, Clutt3R-Seg achieves an AP@25 of 61.66, over 2.2x higher than baselines, and with only four input views it surpasses MaskClustering with eight views by more than 2x. The code is available at: https://github.com/jeonghonoh/clutt3r-seg.
Informative Object-centric Next Best View for Object-aware 3D Gaussian Splatting in Cluttered Scenes
Feb 09, 2026In cluttered scenes with inevitable occlusions and incomplete observations, selecting informative viewpoints is essential for building a reliable representation. In this context, 3D Gaussian Splatting (3DGS) offers a distinct advantage, as it can explicitly guide the selection of subsequent viewpoints and then refine the representation with new observations. However, existing approaches rely solely on geometric cues, neglect manipulation-relevant semantics, and tend to prioritize exploitation over exploration. To tackle these limitations, we introduce an instance-aware Next Best View (NBV) policy that prioritizes underexplored regions by leveraging object features. Specifically, our object-aware 3DGS distills instancelevel information into one-hot object vectors, which are used to compute confidence-weighted information gain that guides the identification of regions associated with erroneous and uncertain Gaussians. Furthermore, our method can be easily adapted to an object-centric NBV, which focuses view selection on a target object, thereby improving reconstruction robustness to object placement. Experiments demonstrate that our NBV policy reduces depth error by up to 77.14% on the synthetic dataset and 34.10% on the real-world GraspNet dataset compared to baselines. Moreover, compared to targeting the entire scene, performing NBV on a specific object yields an additional reduction of 25.60% in depth error for that object. We further validate the effectiveness of our approach through real-world robotic manipulation tasks.
THE-Pose: Topological Prior with Hybrid Graph Fusion for Estimating Category-Level 6D Object Pose
Dec 11, 2025Category-level object pose estimation requires both global context and local structure to ensure robustness against intra-class variations. However, 3D graph convolution (3D-GC) methods only focus on local geometry and depth information, making them vulnerable to complex objects and visual ambiguities. To address this, we present THE-Pose, a novel category-level 6D pose estimation framework that leverages a topological prior via surface embedding and hybrid graph fusion. Specifically, we extract consistent and invariant topological features from the image domain, effectively overcoming the limitations inherent in existing 3D-GC based methods. Our Hybrid Graph Fusion (HGF) module adaptively integrates the topological features with point-cloud features, seamlessly bridging 2D image context and 3D geometric structure. These fused features ensure stability for unseen or complicated objects, even under significant occlusions. Extensive experiments on the REAL275 dataset show that THE-Pose achieves a 35.8% improvement over the 3D-GC baseline (HS-Pose) and surpasses the previous state-of-the-art by 7.2% across all key metrics. The code is avaialbe on https://github.com/EHxxx/THE-Pose
Automatic Channel Pruning for Multi-Head Attention
May 31, 2024Despite the strong performance of Transformers, their quadratic computation complexity presents challenges in applying them to vision tasks. Automatic pruning is one of effective methods for reducing computation complexity without heuristic approaches. However, directly applying it to multi-head attention is not straightforward due to channel misalignment. In this paper, we propose an automatic channel pruning method to take into account the multi-head attention mechanism. First, we incorporate channel similarity-based weights into the pruning indicator to preserve more informative channels in each head. Then, we adjust pruning indicator to enforce removal of channels in equal proportions across all heads, preventing the channel misalignment. We also add a reweight module to compensate for information loss resulting from channel removal, and an effective initialization step for pruning indicator based on difference of attention between original structure and each channel. Our proposed method can be used to not only original attention, but also linear attention, which is more efficient as linear complexity with respect to the number of tokens. On ImageNet-1K, applying our pruning method to the FLattenTransformer, which includes both attention mechanisms, shows outperformed accuracy for several MACs compared with previous state-of-the-art efficient models and pruned methods. Code will be available soon.
Toward Robust LiDAR based 3D Object Detection via Density-Aware Adaptive Thresholding
Apr 22, 2024



Robust 3D object detection is a core challenge for autonomous mobile systems in field robotics. To tackle this issue, many researchers have demonstrated improvements in 3D object detection performance in datasets. However, real-world urban scenarios with unstructured and dynamic situations can still lead to numerous false positives, posing a challenge for robust 3D object detection models. This paper presents a post-processing algorithm that dynamically adjusts object detection thresholds based on the distance from the ego-vehicle. 3D object detection models usually perform well in detecting nearby objects but may exhibit suboptimal performance for distant ones. While conventional perception algorithms typically employ a single threshold in post-processing, the proposed algorithm addresses this issue by employing adaptive thresholds based on the distance from the ego-vehicle, minimizing false negatives and reducing false positives in urban scenarios. The results show performance enhancements in 3D object detection models across a range of scenarios, not only in dynamic urban road conditions but also in scenarios involving adverse weather conditions.
NeuroFlow: Development of lightweight and efficient model integration scheduling strategy for autonomous driving system
Dec 15, 2023This paper proposes a specialized autonomous driving system that takes into account the unique constraints and characteristics of automotive systems, aiming for innovative advancements in autonomous driving technology. The proposed system systematically analyzes the intricate data flow in autonomous driving and provides functionality to dynamically adjust various factors that influence deep learning models. Additionally, for algorithms that do not rely on deep learning models, the system analyzes the flow to determine resource allocation priorities. In essence, the system optimizes data flow and schedules efficiently to ensure real-time performance and safety. The proposed system was implemented in actual autonomous vehicles and experimentally validated across various driving scenarios. The experimental results provide evidence of the system's stable inference and effective control of autonomous vehicles, marking a significant turning point in the development of autonomous driving systems.
One-to-many Approach for Improving Super-Resolution
Jun 22, 2021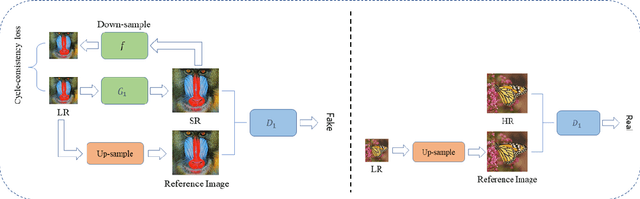
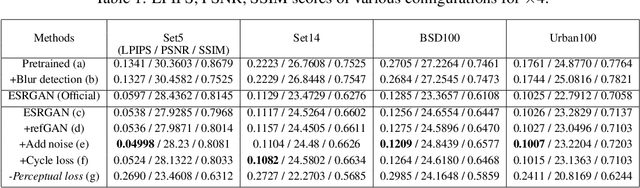
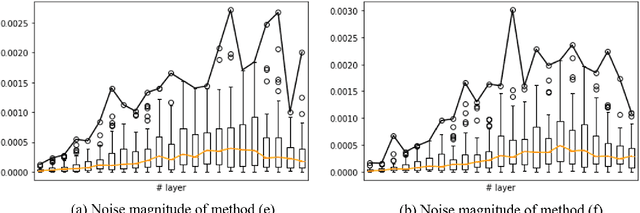
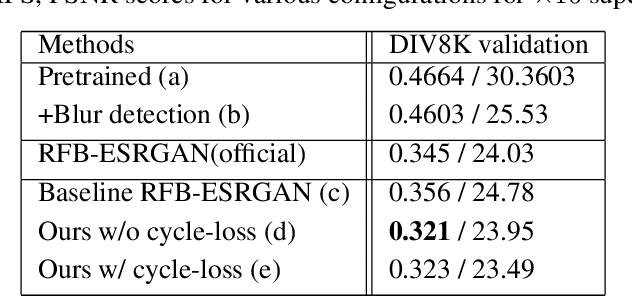
Super-resolution (SR) is a one-to-many task with multiple possible solutions. However, previous works were not concerned about this characteristic. For a one-to-many pipeline, the generator should be able to generate multiple estimates of the reconstruction, and not be penalized for generating similar and equally realistic images. To achieve this, we propose adding weighted pixel-wise noise after every Residual-in-Residual Dense Block (RRDB) to enable the generator to generate various images. We modify the strict content loss to not penalize the stochastic variation in reconstructed images as long as it has consistent content. Additionally, we observe that there are out-of-focus regions in the DIV2K, DIV8K datasets that provide unhelpful guidelines. We filter blurry regions in the training data using the method of [10]. Finally, we modify the discriminator to receive the low-resolution image as a reference image along with the target image to provide better feedback to the generator. Using our proposed methods, we were able to improve the performance of ESRGAN in x4 perceptual SR and achieve the state-of-the-art LPIPS score in x16 perceptual extreme SR.