 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Channel Pruning for Multi-Head Attention
May 31, 2024Despite the strong performance of Transformers, their quadratic computation complexity presents challenges in applying them to vision tasks. Automatic pruning is one of effective methods for reducing computation complexity without heuristic approaches. However, directly applying it to multi-head attention is not straightforward due to channel misalignment. In this paper, we propose an automatic channel pruning method to take into account the multi-head attention mechanism. First, we incorporate channel similarity-based weights into the pruning indicator to preserve more informative channels in each head. Then, we adjust pruning indicator to enforce removal of channels in equal proportions across all heads, preventing the channel misalignment. We also add a reweight module to compensate for information loss resulting from channel removal, and an effective initialization step for pruning indicator based on difference of attention between original structure and each channel. Our proposed method can be used to not only original attention, but also linear attention, which is more efficient as linear complexity with respect to the number of tokens. On ImageNet-1K, applying our pruning method to the FLattenTransformer, which includes both attention mechanisms, shows outperformed accuracy for several MACs compared with previous state-of-the-art efficient models and pruned methods. Code will be available soon.
Robust Deep Multi-modal Learning Based on Gated Information Fusion Network
Nov 02, 2018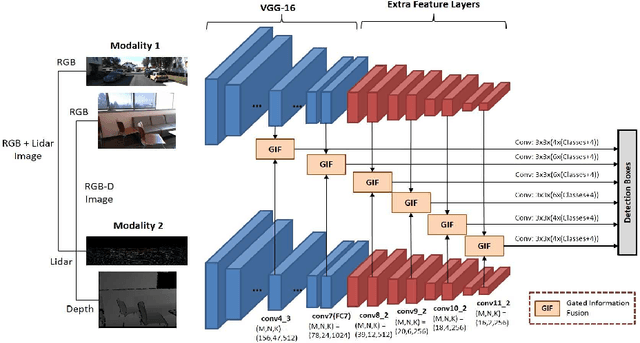
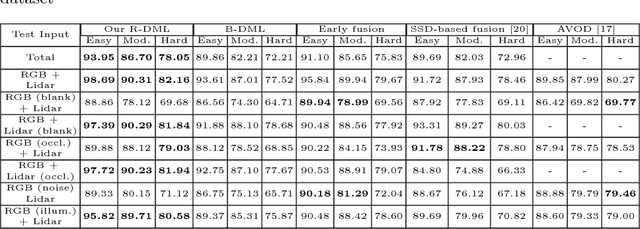
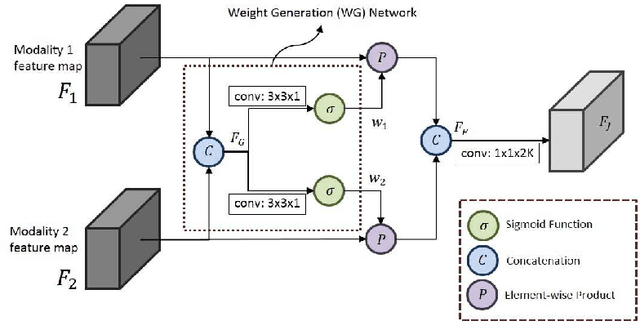
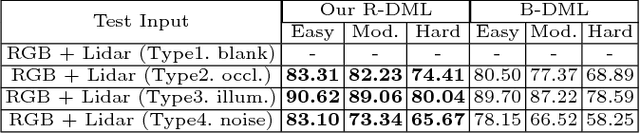
The goal of multi-modal learning is to use complimentary information on the relevant task provided by the multiple modalities to achieve reliable and robust performance. Recently, deep learning has led significant improvement in multi-modal learning by allowing for the information fusion in the intermediate feature levels. This paper addresses a problem of designing robust deep multi-modal learning architecture in the presence of imperfect modalities. We introduce deep fusion architecture for object detection which processes each modality using the separate convolutional neural network (CNN) and constructs the joint feature map by combining the intermediate features from the CNNs. In order to facilitate the robustness to the degraded modalities, we employ the gated information fusion (GIF) network which weights the contribution from each modality according to the input feature maps to be fused. The weights are determined through the convolutional layers followed by a sigmoid function and trained along with the information fusion network in an end-to-end fashion. Our experiments show that the proposed GIF network offers the additional architectural flexibility to achieve robust performance in handling some degraded modalities, and show a significant performance improvement based on Single Shot Detector (SSD) for KITTI dataset using the proposed fusion network and data augmentation schemes.
Detecting Temporally Consistent Objects in Videos through Object Class Label Propagation
Jan 20, 2016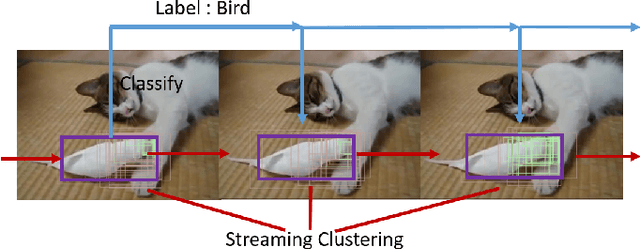
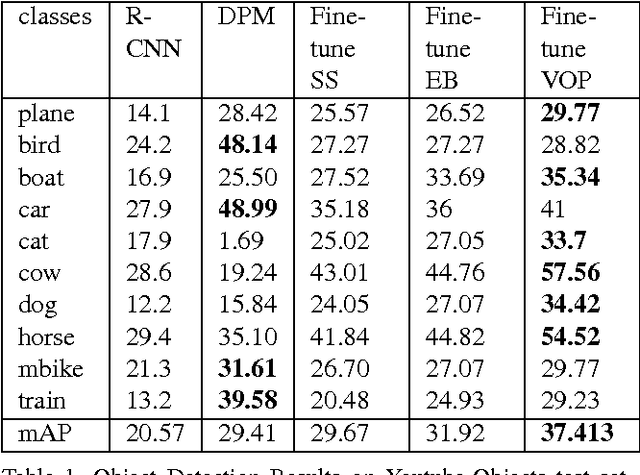


Object proposals for detecting moving or static video objects need to address issues such as speed, memory complexity and temporal consistency. We propose an efficient Video Object Proposal (VOP) generation method and show its efficacy in learning a better video object detector. A deep-learning based video object detector learned using the proposed VOP achieves state-of-the-art detection performance on the Youtube-Objects dataset. We further propose a clustering of VOPs which can efficiently be used for detecting objects in video in a streaming fashion. As opposed to applying per-frame convolutional neural network (CNN) based object detection, our proposed method called Objects in Video Enabler thRough LAbel Propagation (OVERLAP) needs to classify only a small fraction of all candidate proposals in every video frame through streaming clustering of object proposals and class-label propagation. Source code will be made available soon.
Semantic Video Segmentation : Exploring Inference Efficiency
Sep 04, 2015
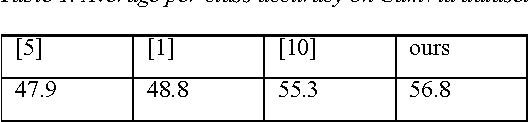
We explore the efficiency of the CRF inference beyond image level semantic segmentation and perform joint inference in video frames. The key idea is to combine best of two worlds: semantic co-labeling and more expressive models. Our formulation enables us to perform inference over ten thousand images within seconds and makes the system amenable to perform video semantic segmentation most effectively. On CamVid dataset, with TextonBoost unaries, our proposed method achieves up to 8% improvement in accuracy over individual semantic image segmentation without additional time overhead. The source code is available at https://github.com/subtri/video_inference
Improving Streaming Video Segmentation with Early and Mid-Level Visual Processing
Feb 14, 2014
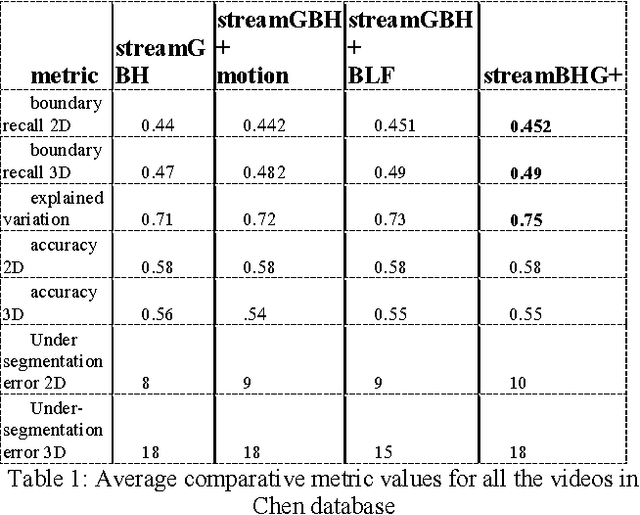
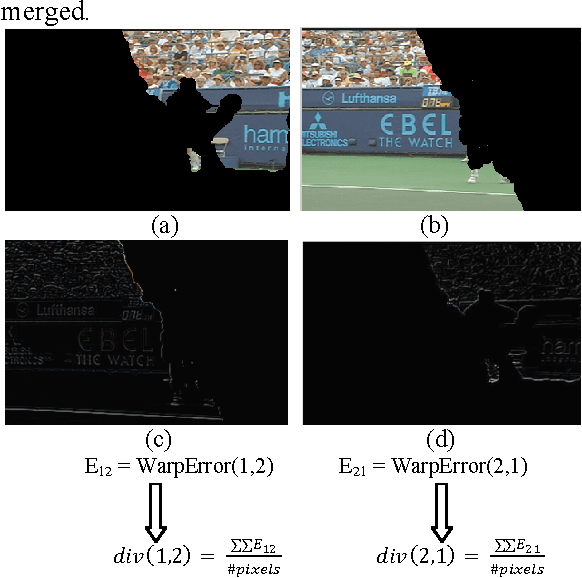
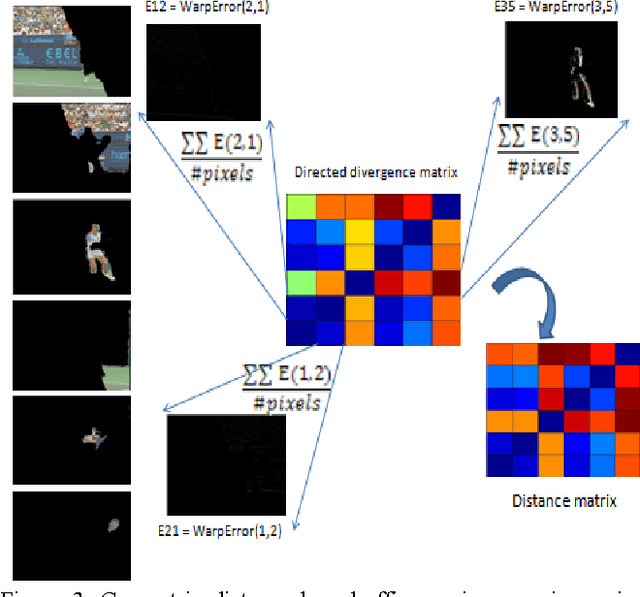
Despite recent advances in video segmentation, many opportunities remain to improve it using a variety of low and mid-level visual cues. We propose improvements to the leading streaming graph-based hierarchical video segmentation (streamGBH) method based on early and mid level visual processing. The extensive experimental analysis of our approach validates the improvement of hierarchical supervoxel representation by incorporating motion and color with effective filtering. We also pose and illuminate some open questions towards intermediate level video analysis as further extension to streamGBH. We exploit the supervoxels as an initialization towards estimation of dominant affine motion regions, followed by merging of such motion regions in order to hierarchically segment a video in a novel motion-segmentation framework which aims at subsequent applications such as foreground recognition.