Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Video Segmentation : Exploring Inference Efficiency
Paper and Code

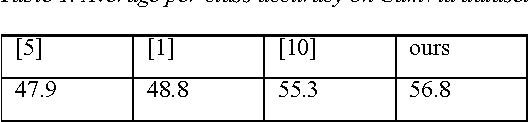
We explore the efficiency of the CRF inference beyond image level semantic segmentation and perform joint inference in video frames. The key idea is to combine best of two worlds: semantic co-labeling and more expressive models. Our formulation enables us to perform inference over ten thousand images within seconds and makes the system amenable to perform video semantic segmentation most effectively. On CamVid dataset, with TextonBoost unaries, our proposed method achieves up to 8% improvement in accuracy over individual semantic image segmentation without additional time overhead. The source code is available at https://github.com/subtri/video_inference
* To appear in proc of ISOCC 2015
View paper on