Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleash the Potential of CLIP for Video Highlight Detection
Paper and Code
Apr 02, 2024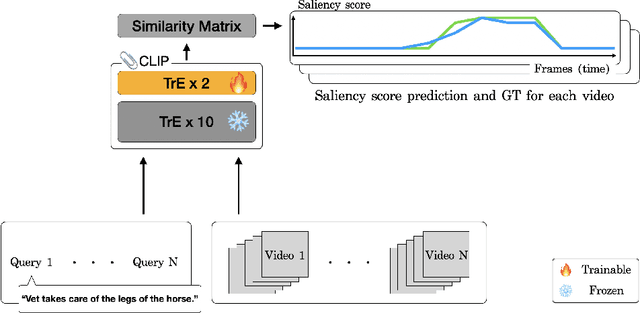
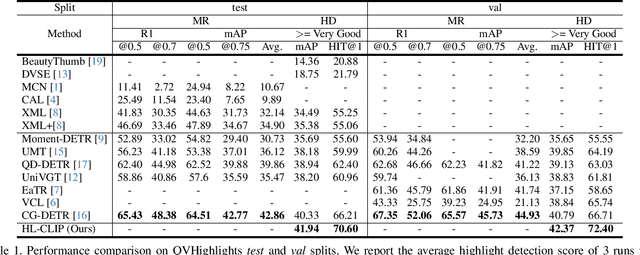
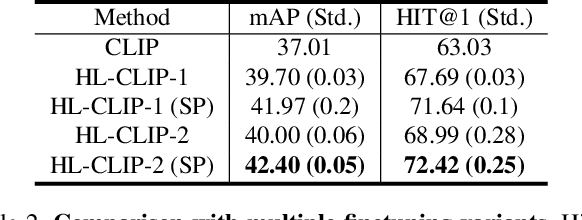
Multimodal and large language models (LLMs) have revolutionized the utilization of open-world knowledge, unlocking novel potentials across various tasks and applications. Among these domains, the video domain has notably benefited from their capabilities. In this paper, we present Highlight-CLIP (HL-CLIP), a method designed to excel in the video highlight detection task by leveraging the pre-trained knowledge embedded in multimodal models. By simply fine-tuning the multimodal encoder in combination with our innovative saliency pooling technique, we have achieved the state-of-the-art performance in the highlight detection task, the QVHighlight Benchmark, to the best of our knowledge.
View paper on