 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe U-Net based GLOW for Optical-Flow-free Video Interframe Generation
Apr 06, 2021
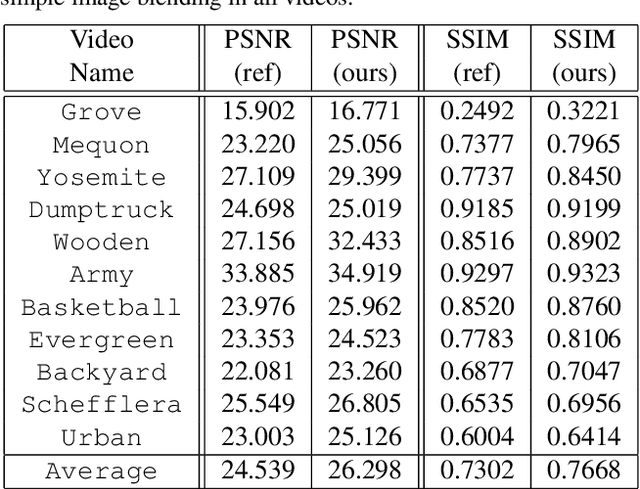
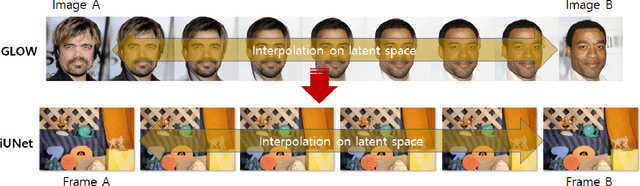
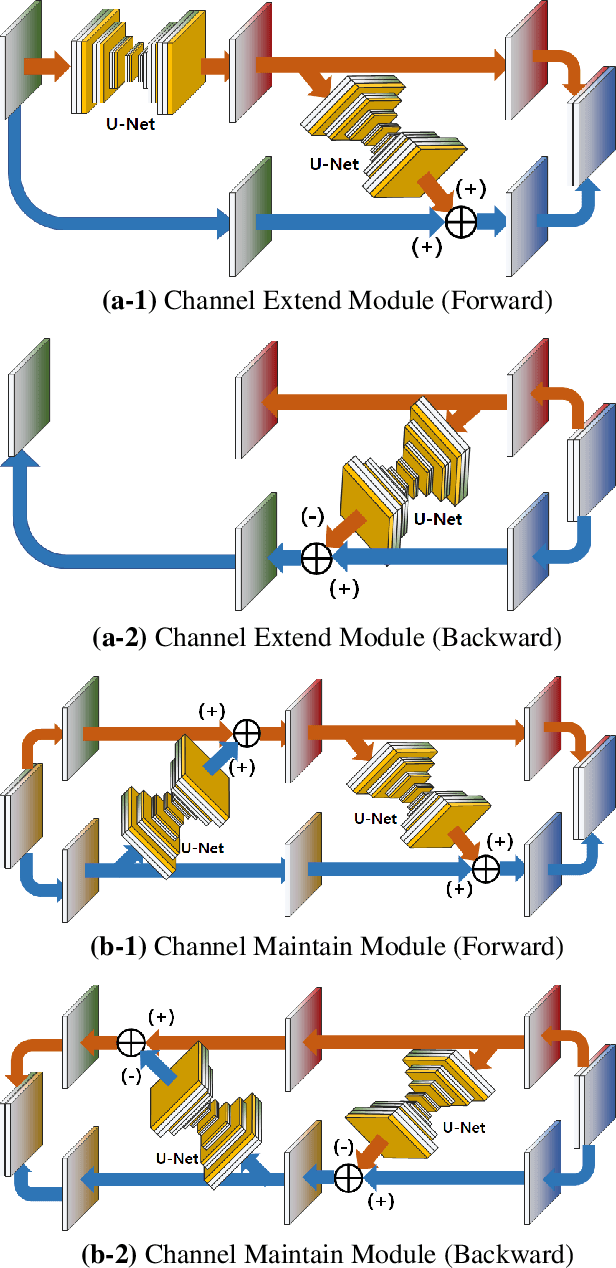
Video frame interpolation is the task of creating an interframe between two adjacent frames along the time axis. So, instead of simply averaging two adjacent frames to create an intermediate image, this operation should maintain semantic continuity with the adjacent frames. Most conventional methods use optical flow, and various tools such as occlusion handling and object smoothing are indispensable. Since the use of these various tools leads to complex problems, we tried to tackle the video interframe generation problem without using problematic optical flow . To enable this , we have tried to use a deep neural network with an invertible structure, and developed an U-Net based Generative Flow which is a modified normalizing flow. In addition, we propose a learning method with a new consistency loss in the latent space to maintain semantic temporal consistency between frames. The resolution of the generated image is guaranteed to be identical to that of the original images by using an invertible network. Furthermore, as it is not a random image like the ones by generative models, our network guarantees stable outputs without flicker. Through experiments, we \sam {confirmed the feasibility of the proposed algorithm and would like to suggest the U-Net based Generative Flow as a new possibility for baseline in video frame interpolation. This paper is meaningful in that it is the world's first attempt to use invertible networks instead of optical flows for video interpolation.
Image Enhancement by Recurrently-trained Super-resolution Network
Jul 26, 2019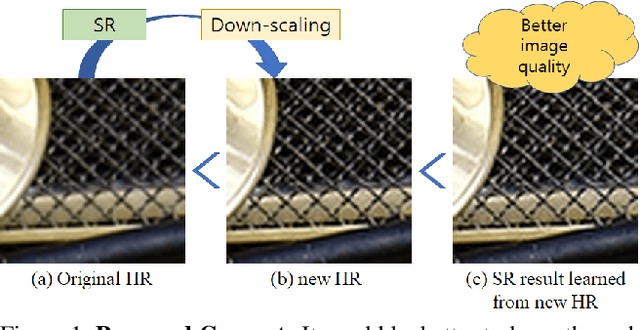
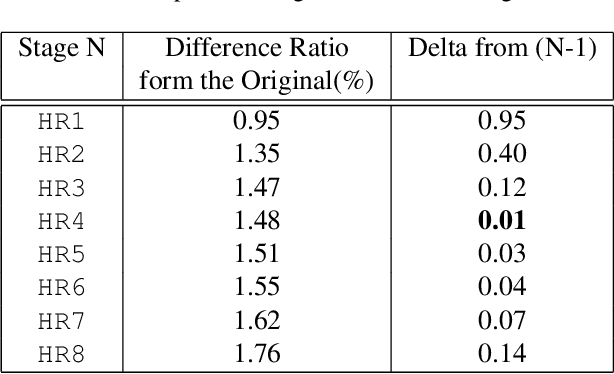

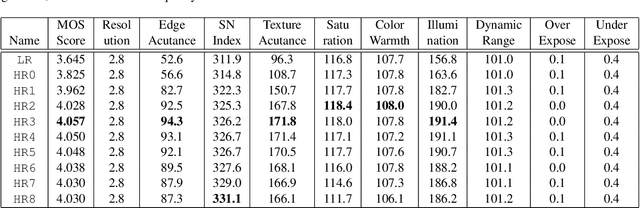
We introduce a new learning strategy for image enhancement by recurrently training the same simple superresolution (SR) network multiple times. After initially training an SR network by using pairs of a corrupted low resolution (LR) image and an original image, the proposed method makes use of the trained SR network to generate new high resolution (HR) images with a doubled resolution from the original uncorrupted images. Then, the new HR images are downscaled to the original resolution, which work as target images for the SR network in the next stage. The newly generated HR images by the repeatedly trained SR network show better image quality and this strategy of training LR to mimic new HR can lead to a more efficient SR network. Up to a certain point, by repeating this process multiple times, better and better images are obtained. This recurrent leaning strategy for SR can be a good solution for downsizing convolution networks and making a more efficient SR network. To measure the enhanced image quality, for the first time in this area of super-resolution and image enhancement, we use VIQET MOS score which reflects human visual quality more accurately than the conventional MSE measure.