 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaint by Word
Mar 24, 2021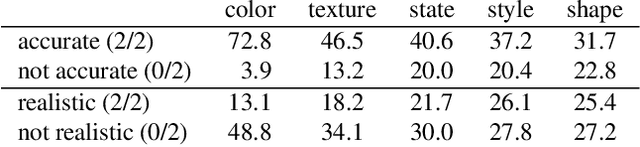
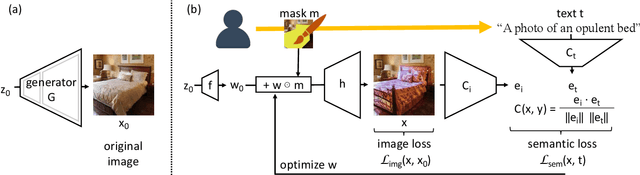

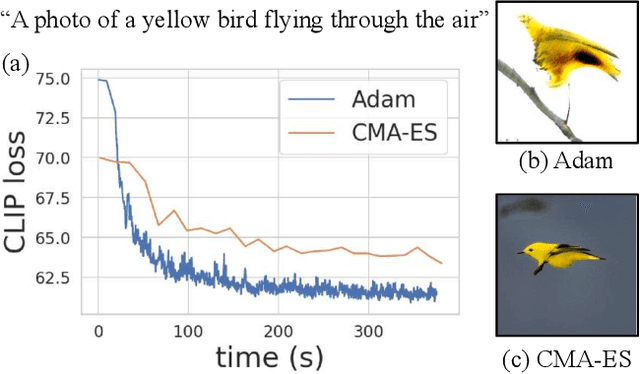
We investigate the problem of zero-shot semantic image painting. Instead of painting modifications into an image using only concrete colors or a finite set of semantic concepts, we ask how to create semantic paint based on open full-text descriptions: our goal is to be able to point to a location in a synthesized image and apply an arbitrary new concept such as "rustic" or "opulent" or "happy dog." To do this, our method combines a state-of-the art generative model of realistic images with a state-of-the-art text-image semantic similarity network. We find that, to make large changes, it is important to use non-gradient methods to explore latent space, and it is important to relax the computations of the GAN to target changes to a specific region. We conduct user studies to compare our methods to several baselines.