 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Learning and Model Analysis with Compositional Data
Paper and Code
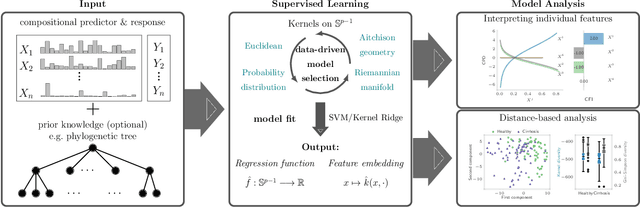

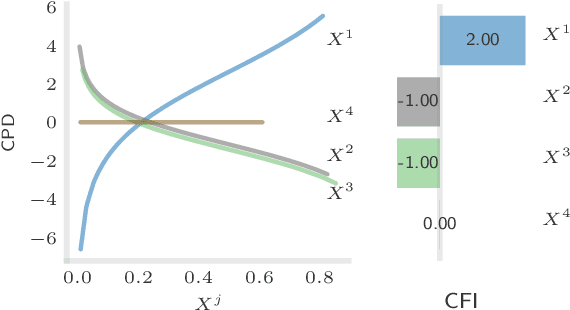
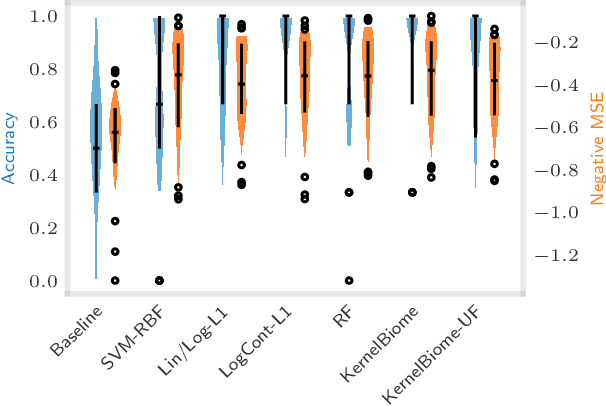
The compositionality and sparsity of high-throughput sequencing data poses a challenge for regression and classification. However, in microbiome research in particular, conditional modeling is an essential tool to investigate relationships between phenotypes and the microbiome. Existing techniques are often inadequate: they either rely on extensions of the linear log-contrast model (which adjusts for compositionality, but is often unable to capture useful signals), or they are based on black-box machine learning methods (which may capture useful signals, but ignore compositionality in downstream analyses). We propose KernelBiome, a kernel-based nonparametric regression and classification framework for compositional data. It is tailored to sparse compositional data and is able to incorporate prior knowledge, such as phylogenetic structure. KernelBiome captures complex signals, including in the zero-structure, while automatically adapting model complexity. We demonstrate on par or improved predictive performance compared with state-of-the-art machine learning methods. Additionally, our framework provides two key advantages: (i) We propose two novel quantities to interpret contributions of individual components and prove that they consistently estimate average perturbation effects of the conditional mean, extending the interpretability of linear log-contrast models to nonparametric models. (ii) We show that the connection between kernels and distances aids interpretability and provides a data-driven embedding that can augment further analysis. Finally, we apply the KernelBiome framework to two public microbiome studies and illustrate the proposed model analysis. KernelBiome is available as an open-source Python package at https://github.com/shimenghuang/KernelBiome.