 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinerva: A File-Based Ransomware Detector
Jan 26, 2023Ransomware is a rapidly evolving type of malware designed to encrypt user files on a device, making them inaccessible in order to exact a ransom. Ransomware attacks resulted in billions of dollars in damages in recent years and are expected to cause hundreds of billions more in the next decade. With current state-of-the-art process-based detectors being heavily susceptible to evasion attacks, no comprehensive solution to this problem is available today. This paper presents Minerva, a new approach to ransomware detection. Unlike current methods focused on identifying ransomware based on process-level behavioral modeling, Minerva detects ransomware by building behavioral profiles of files based on all the operations they receive in a time window. Minerva addresses some of the critical challenges associated with process-based approaches, specifically their vulnerability to complex evasion attacks. Our evaluation of Minerva demonstrates its effectiveness in detecting ransomware attacks, including those that are able to bypass existing defenses. Our results show that Minerva identifies ransomware activity with an average accuracy of 99.45% and an average recall of 99.66%, with 99.97% of ransomware detected within 1 second.
Reliable Detection of Compressed and Encrypted Data
Mar 31, 2021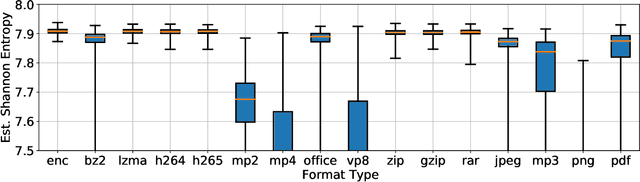
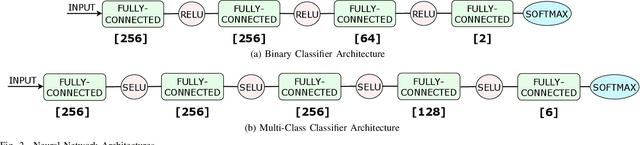
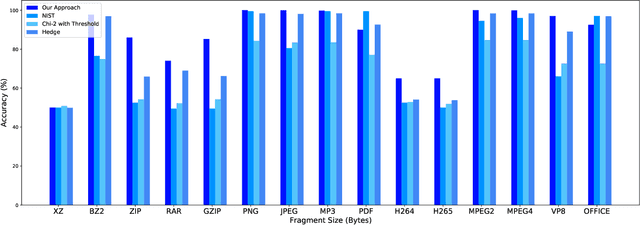
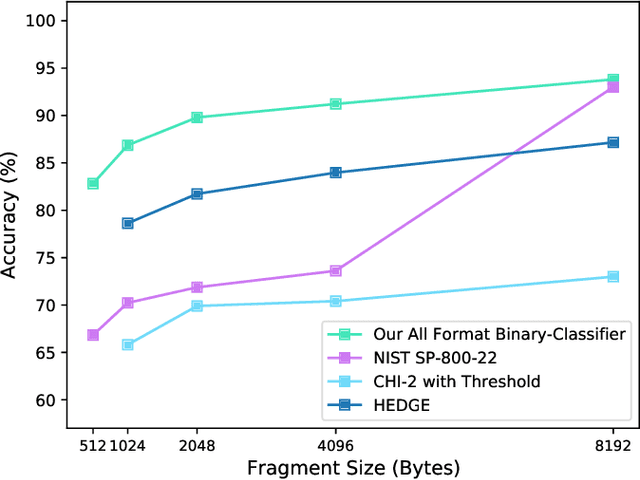
Several cybersecurity domains, such as ransomware detection, forensics and data analysis, require methods to reliably identify encrypted data fragments. Typically, current approaches employ statistics derived from byte-level distribution, such as entropy estimation, to identify encrypted fragments. However, modern content types use compression techniques which alter data distribution pushing it closer to the uniform distribution. The result is that current approaches exhibit unreliable encryption detection performance when compressed data appears in the dataset. Furthermore, proposed approaches are typically evaluated over few data types and fragment sizes, making it hard to assess their practical applicability. This paper compares existing statistical tests on a large, standardized dataset and shows that current approaches consistently fail to distinguish encrypted and compressed data on both small and large fragment sizes. We address these shortcomings and design EnCoD, a learning-based classifier which can reliably distinguish compressed and encrypted data. We evaluate EnCoD on a dataset of 16 different file types and fragment sizes ranging from 512B to 8KB. Our results highlight that EnCoD outperforms current approaches by a wide margin, with accuracy ranging from ~82 for 512B fragments up to ~92 for 8KB data fragments. Moreover, EnCoD can pinpoint the exact format of a given data fragment, rather than performing only binary classification like previous approaches.
EnCoD: Distinguishing Compressed and Encrypted File Fragments
Oct 15, 2020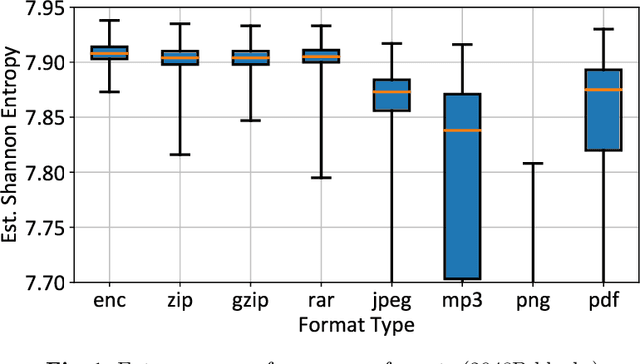
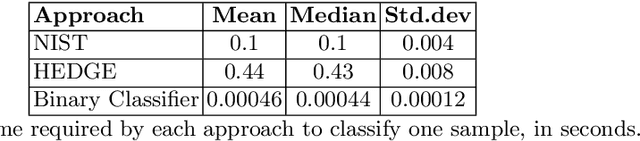
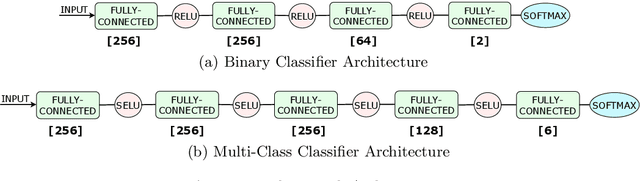
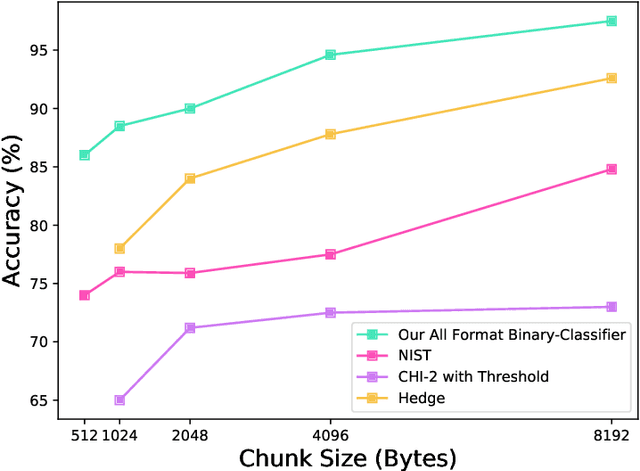
Reliable identification of encrypted file fragments is a requirement for several security applications, including ransomware detection, digital forensics, and traffic analysis. A popular approach consists of estimating high entropy as a proxy for randomness. However, many modern content types (e.g. office documents, media files, etc.) are highly compressed for storage and transmission efficiency. Compression algorithms also output high-entropy data, thus reducing the accuracy of entropy-based encryption detectors. Over the years, a variety of approaches have been proposed to distinguish encrypted file fragments from high-entropy compressed fragments. However, these approaches are typically only evaluated over a few, select data types and fragment sizes, which makes a fair assessment of their practical applicability impossible. This paper aims to close this gap by comparing existing statistical tests on a large, standardized dataset. Our results show that current approaches cannot reliably tell apart encryption and compression, even for large fragment sizes. To address this issue, we design EnCoD, a learning-based classifier which can reliably distinguish compressed and encrypted data, starting with fragments as small as 512 bytes. We evaluate EnCoD against current approaches over a large dataset of different data types, showing that it outperforms current state-of-the-art for most considered fragment sizes and data types.
The Naked Sun: Malicious Cooperation Between Benign-Looking Processes
Nov 06, 2019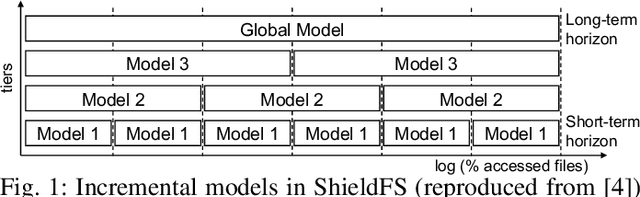
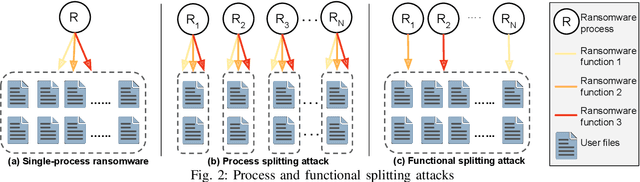
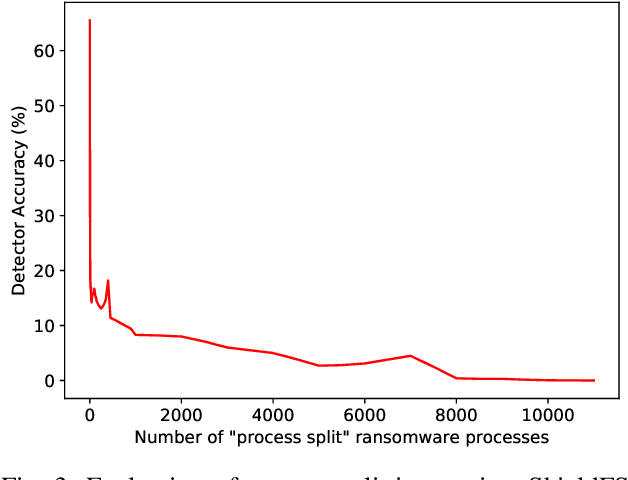
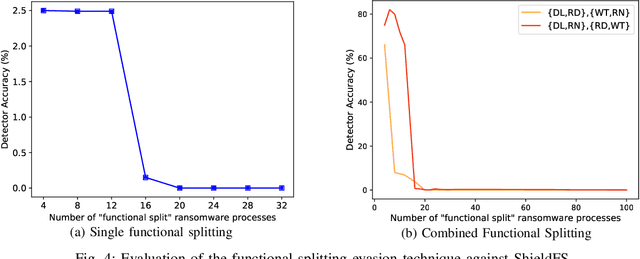
Recent progress in machine learning has generated promising results in behavioral malware detection. Behavioral modeling identifies malicious processes via features derived by their runtime behavior. Behavioral features hold great promise as they are intrinsically related to the functioning of each malware, and are therefore considered difficult to evade. Indeed, while a significant amount of results exists on evasion of static malware features, evasion of dynamic features has seen limited work. This paper thoroughly examines the robustness of behavioral malware detectors to evasion, focusing particularly on anti-ransomware evasion. We choose ransomware as its behavior tends to differ significantly from that of benign processes, making it a low-hanging fruit for behavioral detection (and a difficult candidate for evasion). Our analysis identifies a set of novel attacks that distribute the overall malware workload across a small set of cooperating processes to avoid the generation of significant behavioral features. Our most effective attack decreases the accuracy of a state-of-the-art classifier from 98.6% to 0% using only 18 cooperating processes. Furthermore, we show our attacks to be effective against commercial ransomware detectors even in a black-box setting.