 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOliVaR: Improving Olive Variety Recognition using Deep Neural Networks
Mar 01, 2023

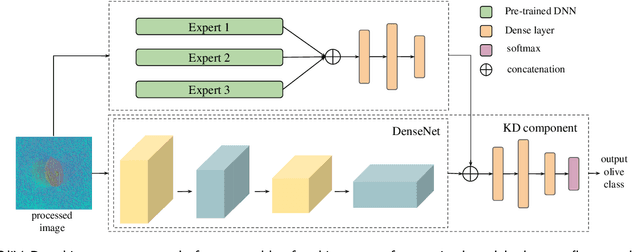

The easy and accurate identification of varieties is fundamental in agriculture, especially in the olive sector, where more than 1200 olive varieties are currently known worldwide. Varietal misidentification leads to many potential problems for all the actors in the sector: farmers and nursery workers may establish the wrong variety, leading to its maladaptation in the field; olive oil and table olive producers may label and sell a non-authentic product; consumers may be misled; and breeders may commit errors during targeted crossings between different varieties. To date, the standard for varietal identification and certification consists of two methods: morphological classification and genetic analysis. The morphological classification consists of the visual pairwise comparison of different organs of the olive tree, where the most important organ is considered to be the endocarp. In contrast, different methods for genetic classification exist (RAPDs, SSR, and SNP). Both classification methods present advantages and disadvantages. Visual morphological classification requires highly specialized personnel and is prone to human error. Genetic identification methods are more accurate but incur a high cost and are difficult to implement. This paper introduces OliVaR, a novel approach to olive varietal identification. OliVaR uses a teacher-student deep learning architecture to learn the defining characteristics of the endocarp of each specific olive variety and perform classification. We construct what is, to the best of our knowledge, the largest olive variety dataset to date, comprising image data for 131 varieties from the Mediterranean basin. We thoroughly test OliVaR on this dataset and show that it correctly predicts olive varieties with over 86% accuracy.