 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHave You Poisoned My Data? Defending Neural Networks against Data Poisoning
Paper and Code
Mar 20, 2024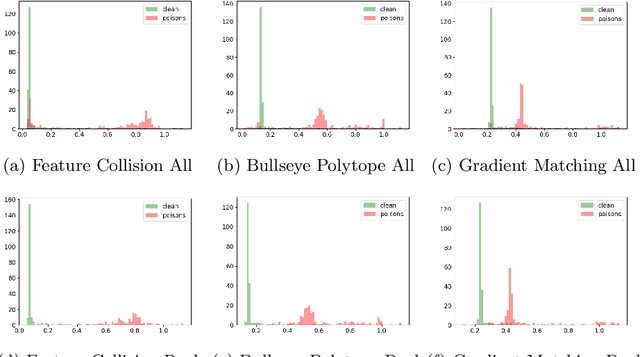



The unprecedented availability of training data fueled the rapid development of powerful neural networks in recent years. However, the need for such large amounts of data leads to potential threats such as poisoning attacks: adversarial manipulations of the training data aimed at compromising the learned model to achieve a given adversarial goal. This paper investigates defenses against clean-label poisoning attacks and proposes a novel approach to detect and filter poisoned datapoints in the transfer learning setting. We define a new characteristic vector representation of datapoints and show that it effectively captures the intrinsic properties of the data distribution. Through experimental analysis, we demonstrate that effective poisons can be successfully differentiated from clean points in the characteristic vector space. We thoroughly evaluate our proposed approach and compare it to existing state-of-the-art defenses using multiple architectures, datasets, and poison budgets. Our evaluation shows that our proposal outperforms existing approaches in defense rate and final trained model performance across all experimental settings.