 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Nephrographic Image Synthesis in CT Urography with the Diffusion Model and Swin Transformer
Feb 26, 2025Purpose: This study aims to develop and validate a method for synthesizing 3D nephrographic phase images in CT urography (CTU) examinations using a diffusion model integrated with a Swin Transformer-based deep learning approach. Materials and Methods: This retrospective study was approved by the local Institutional Review Board. A dataset comprising 327 patients who underwent three-phase CTU (mean $\pm$ SD age, 63 $\pm$ 15 years; 174 males, 153 females) was curated for deep learning model development. The three phases for each patient were aligned with an affine registration algorithm. A custom deep learning model coined dsSNICT (diffusion model with a Swin transformer for synthetic nephrographic phase images in CT) was developed and implemented to synthesize the nephrographic images. Performance was assessed using Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), Mean Absolute Error (MAE), and Fr\'{e}chet Video Distance (FVD). Qualitative evaluation by two fellowship-trained abdominal radiologists was performed. Results: The synthetic nephrographic images generated by our proposed approach achieved high PSNR (26.3 $\pm$ 4.4 dB), SSIM (0.84 $\pm$ 0.069), MAE (12.74 $\pm$ 5.22 HU), and FVD (1323). Two radiologists provided average scores of 3.5 for real images and 3.4 for synthetic images (P-value = 0.5) on a Likert scale of 1-5, indicating that our synthetic images closely resemble real images. Conclusion: The proposed approach effectively synthesizes high-quality 3D nephrographic phase images. This model can be used to reduce radiation dose in CTU by 33.3\% without compromising image quality, which thereby enhances the safety and diagnostic utility of CT urography.
Small Business Classification By Name: Addressing Gender and Geographic Origin Biases
Dec 18, 2020


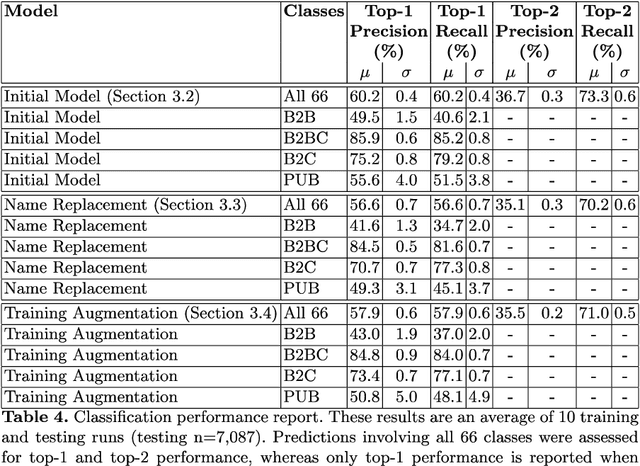
Small business classification is a difficult and important task within many applications, including customer segmentation. Training on small business names introduces gender and geographic origin biases. A model for predicting one of 66 business types based only upon the business name was developed in this work (top-1 f1-score = 60.2%). Two approaches to removing the bias from this model are explored: replacing given names with a placeholder token, and augmenting the training data with gender-swapped examples. The results for these approaches is reported, and the bias in the model was reduced by hiding given names from the model. However, bias reduction was accomplished at the expense of classification performance (top-1 f1-score = 56.6%). Augmentation of the training data with gender-swapping samples proved less effective at bias reduction than the name hiding approach on the evaluated dataset.