 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTake It or Leave It: Intent-Controlled Partial Optimal Transport
May 19, 2026While optimal transport (OT) enforces a rigid constraint by requiring two measures to be matched exactly, partial optimal transport relaxes this requirement by allowing mass to remain unmatched through a global budget, scalar rebate, or uniform rejection rule. However, many applications call for more structured, pointwise rejection mechanisms, where the decision to leave mass unmatched depends on side-specific reliability, support geometry, or external information about which components should participate in the comparison. We introduce \emph{intent-controlled partial optimal transport} (IC-POT), a targeted generalization of partial transport that replaces the global rejection paradigm with pointwise rejection costs over both measures. We show that the resulting optimization problem admits a dual interpretation in terms of local acceptance thresholds and can be solved by recasting it as a balanced Kantorovich OT problem on an augmented support. Beyond theoretical analysis, we demonstrate the practical relevance of IC-POT in settings where rejection is driven by side information. In positive-unlabeled learning and open-partial domain adaptation, incorporating pointwise rejection rules that encode statistical structure improves fixed baseline pipelines. Finally, we motivate the use of IC-POT with a geophysical practical case: multi-modal satellite ocean measurements, for which physical and sensors priors naturally inform the rejection mechanism and define the retrieved comparable signal information.
Static and auto-regressive neural emulation of phytoplankton biomass dynamics from physical predictors in the global ocean
Feb 04, 2026Phytoplankton is the basis of marine food webs, driving both ecological processes and global biogeochemical cycles. Despite their ecological and climatic significance, accurately simulating phytoplankton dynamics remains a major challenge for biogeochemical numerical models due to limited parameterizations, sparse observational data, and the complexity of oceanic processes. Here, we explore how deep learning models can be used to address these limitations predicting the spatio-temporal distribution of phytoplankton biomass in the global ocean based on satellite observations and environmental conditions. First, we investigate several deep learning architectures. Among the tested models, the UNet architecture stands out for its ability to reproduce the seasonal and interannual patterns of phytoplankton biomass more accurately than other models like CNNs, ConvLSTM, and 4CastNet. When using one to two months of environmental data as input, UNet performs better, although it tends to underestimate the amplitude of low-frequency changes in phytoplankton biomass. Thus, to improve predictions over time, an auto-regressive version of UNet was also tested, where the model uses its own previous predictions to forecast future conditions. This approach works well for short-term forecasts (up to five months), though its performance decreases for longer time scales. Overall, our study shows that combining ocean physical predictors with deep learning allows for reconstruction and short-term prediction of phytoplankton dynamics. These models could become powerful tools for monitoring ocean health and supporting marine ecosystem management, especially in the context of climate change.
Discovering Data Manifold Geometry via Non-Contracting Flows
Feb 02, 2026We introduce an unsupervised approach for constructing a global reference system by learning, in the ambient space, vector fields that span the tangent spaces of an unknown data manifold. In contrast to isometric objectives, which implicitly assume manifold flatness, our method learns tangent vector fields whose flows transport all samples to a common, learnable reference point. The resulting arc-lengths along these flows define interpretable intrinsic coordinates tied to a shared global frame. To prevent degenerate collapse, we enforce a non-shrinking constraint and derive a scalable, integration-free objective inspired by flow matching. Within our theoretical framework, we prove that minimizing the proposed objective recovers a global coordinate chart when one exists. Empirically, we obtain correct tangent alignment and coherent global coordinate structure on synthetic manifolds. We also demonstrate the scalability of our method on CIFAR-10, where the learned coordinates achieve competitive downstream classification performance.
Neural ocean forecasting from sparse satellite-derived observations: a case-study for SSH dynamics and altimetry data
Dec 15, 2025We present an end-to-end deep learning framework for short-term forecasting of global sea surface dynamics based on sparse satellite altimetry data. Building on two state-of-the-art architectures: U-Net and 4DVarNet, originally developed for image segmentation and spatiotemporal interpolation respectively, we adapt the models to forecast the sea level anomaly and sea surface currents over a 7-day horizon using sequences of sparse nadir altimeters observations. The model is trained on data from the GLORYS12 operational ocean reanalysis, with synthetic nadir sampling patterns applied to simulate realistic observational coverage. The forecasting task is formulated as a sequence-to-sequence mapping, with the input comprising partial sea level anomaly (SLA) snapshots and the target being the corresponding future full-field SLA maps. We evaluate model performance using (i) normalized root mean squared error (nRMSE), (ii) averaged effective resolution, (iii) percentage of correctly predicted velocities magnitudes and angles, and benchmark results against the operational Mercator Ocean forecast product. Results show that end-to-end neural forecasts outperform the baseline across all lead times, with particularly notable improvements in high variability regions. Our framework is developed within the OceanBench benchmarking initiative, promoting reproducibility and standardized evaluation in ocean machine learning. These results demonstrate the feasibility and potential of end-to-end neural forecasting models for operational oceanography, even in data-sparse conditions.
Simulation-informed deep learning for enhanced SWOT observations of fine-scale ocean dynamics
Mar 27, 2025Oceanic processes at fine scales are crucial yet difficult to observe accurately due to limitations in satellite and in-situ measurements. The Surface Water and Ocean Topography (SWOT) mission provides high-resolution Sea Surface Height (SSH) data, though noise patterns often obscure fine scale structures. Current methods struggle with noisy data or require extensive supervised training, limiting their effectiveness on real-world observations. We introduce SIMPGEN (Simulation-Informed Metric and Prior for Generative Ensemble Networks), an unsupervised adversarial learning framework combining real SWOT observations with simulated reference data. SIMPGEN leverages wavelet-informed neural metrics to distinguish noisy from clean fields, guiding realistic SSH reconstructions. Applied to SWOT data, SIMPGEN effectively removes noise, preserving fine-scale features better than existing neural methods. This robust, unsupervised approach not only improves SWOT SSH data interpretation but also demonstrates strong potential for broader oceanographic applications, including data assimilation and super-resolution.
Observation-only learning of neural mapping schemes for gappy satellite-derived ocean colour parameters
Mar 14, 2025
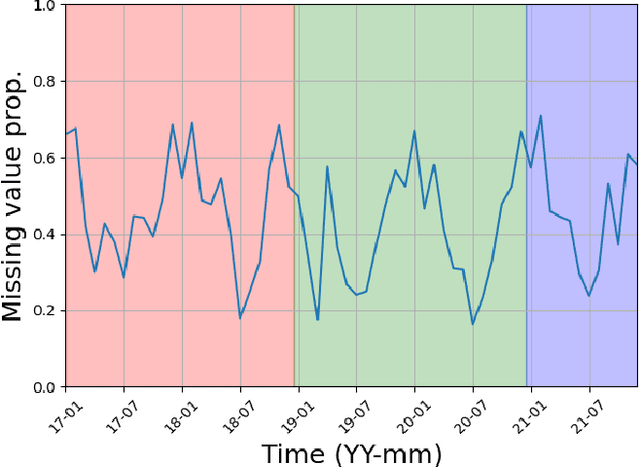

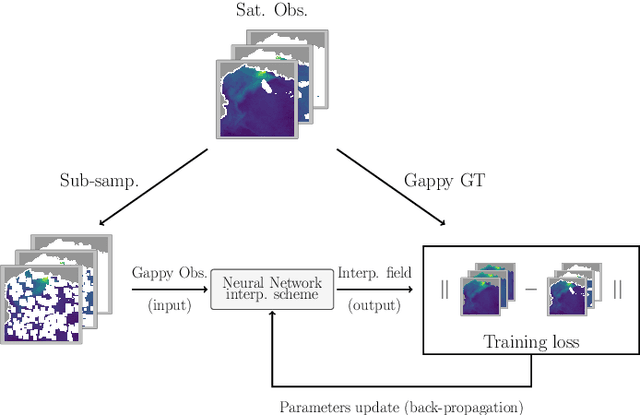
Monitoring optical properties of coastal and open ocean waters is crucial to assessing the health of marine ecosystems. Deep learning offers a promising approach to address these ecosystem dynamics, especially in scenarios where gap-free ground-truth data is lacking, which poses a challenge for designing effective training frameworks. Using an advanced neural variational data assimilation scheme (called 4DVarNet), we introduce a comprehensive training framework designed to effectively train directly on gappy data sets. Using the Mediterranean Sea as a case study, our experiments not only highlight the high performance of the chosen neural network in reconstructing gap-free images from gappy datasets but also demonstrate its superior performance over state-of-the-art algorithms such as DInEOF and Direct Inversion, whether using CNN or UNet architectures.
Generalization performance of neural mapping schemes for the space-time interpolation of satellite-derived ocean colour datasets
Mar 14, 2025

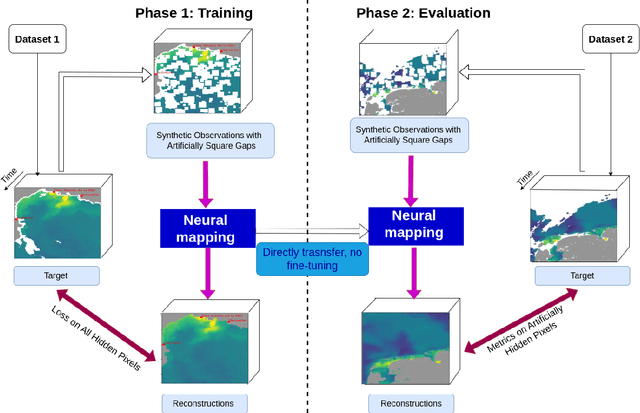
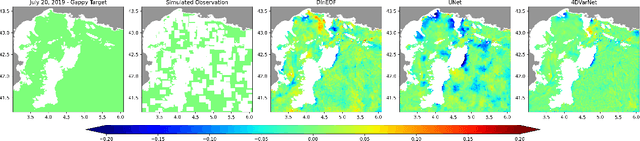
Neural mapping schemes have become appealing approaches to deliver gap-free satellite-derived products for sea surface tracers. The generalization performance of these learning-based approaches naturally arises as a key challenge. This is particularly true for satellite-derived ocean colour products given the variety of bio-optical variables of interest, as well as the diversity of processes and scales involved. Considering region-specific and parameter-specific neural mapping schemes will result in substantial training costs. This study addresses generalization performance of neural mapping schemes to deliver gap-free satellite-derived ocean colour products. We develop a comprehensive experimental framework using real multi-sensor ocean colour datasets for two regions (the Mediterranean Sea and the North Sea) and a representative set of bio-optical parameters (Chlorophyll-a concentration, suspended particulate matter concentration, particulate backscattering coefficient). We consider several neural mapping schemes, and we report excellent generalization performance across regions and bio-optical parameters without any fine-tuning using appropriate dataset-specific normalization procedures. We discuss further how these results provide new insights towards the large-scale deployment of neural schemes for the processing of satellite-derived ocean colour datasets beyond case-study-specific demonstrations.
Neural Incremental Data Assimilation
Jun 21, 2024Data assimilation is a central problem in many geophysical applications, such as weather forecasting. It aims to estimate the state of a potentially large system, such as the atmosphere, from sparse observations, supplemented by prior physical knowledge. The size of the systems involved and the complexity of the underlying physical equations make it a challenging task from a computational point of view. Neural networks represent a promising method of emulating the physics at low cost, and therefore have the potential to considerably improve and accelerate data assimilation. In this work, we introduce a deep learning approach where the physical system is modeled as a sequence of coarse-to-fine Gaussian prior distributions parametrized by a neural network. This allows us to define an assimilation operator, which is trained in an end-to-end fashion to minimize the reconstruction error on a dataset with different observation processes. We illustrate our approach on chaotic dynamical physical systems with sparse observations, and compare it to traditional variational data assimilation methods.
SPDE priors for uncertainty quantification of end-to-end neural data assimilation schemes
Feb 02, 2024



The spatio-temporal interpolation of large geophysical datasets has historically been adressed by Optimal Interpolation (OI) and more sophisticated model-based or data-driven DA techniques. In the last ten years, the link established between Stochastic Partial Differential Equations (SPDE) and Gaussian Markov Random Fields (GMRF) opened a new way of handling both large datasets and physically-induced covariance matrix in Optimal Interpolation. Recent advances in the deep learning community also enables to adress this problem as neural architecture embedding data assimilation variational framework. The reconstruction task is seen as a joint learning problem of the prior involved in the variational inner cost and the gradient-based minimization of the latter: both prior models and solvers are stated as neural networks with automatic differentiation which can be trained by minimizing a loss function, typically stated as the mean squared error between some ground truth and the reconstruction. In this work, we draw from the SPDE-based Gaussian Processes to estimate complex prior models able to handle non-stationary covariances in both space and time and provide a stochastic framework for interpretability and uncertainty quantification. Our neural variational scheme is modified to embed an augmented state formulation with both state and SPDE parametrization to estimate. Instead of a neural prior, we use a stochastic PDE as surrogate model along the data assimilation window. The training involves a loss function for both reconstruction task and SPDE prior model, where the likelihood of the SPDE parameters given the true states is involved in the training. Because the prior is stochastic, we can easily draw samples in the prior distribution before conditioning to provide a flexible way to estimate the posterior distribution based on thousands of members.
Multi-Modal Learning-based Reconstruction of High-Resolution Spatial Wind Speed Fields
Dec 14, 2023



Wind speed at sea surface is a key quantity for a variety of scientific applications and human activities. Due to the non-linearity of the phenomenon, a complete description of such variable is made infeasible on both the small scale and large spatial extents. Methods relying on Data Assimilation techniques, despite being the state-of-the-art for Numerical Weather Prediction, can not provide the reconstructions with a spatial resolution that can compete with satellite imagery. In this work we propose a framework based on Variational Data Assimilation and Deep Learning concepts. This framework is applied to recover rich-in-time, high-resolution information on sea surface wind speed. We design our experiments using synthetic wind data and different sampling schemes for high-resolution and low-resolution versions of original data to emulate the real-world scenario of spatio-temporally heterogeneous observations. Extensive numerical experiments are performed to assess systematically the impact of low and high-resolution wind fields and in-situ observations on the model reconstruction performance. We show that in-situ observations with richer temporal resolution represent an added value in terms of the model reconstruction performance. We show how a multi-modal approach, that explicitly informs the model about the heterogeneity of the available observations, can improve the reconstruction task by exploiting the complementary information in spatial and local point-wise data. To conclude, we propose an analysis to test the robustness of the chosen framework against phase delay and amplitude biases in low-resolution data and against interruptions of in-situ observations supply at evaluation time