 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline learning of subgrid-scale models for quasi-geostrophic turbulence in planetary interiors
Nov 18, 2025



The use of machine learning to represent subgrid-scale (SGS) dynamics is now well established in weather forecasting and climate modelling. Recent advances have demonstrated that SGS models trained via ``online'' end-to-end learning -- where the dynamical solver operating on the filtered equations participates in the training -- can outperform traditional physics-based approaches. Most studies, however, have focused on idealised periodic domains, neglecting the mechanical boundaries present e.g. in planetary interiors. To address this issue, we consider two-dimensional quasi-geostrophic turbulent flow in an axisymmetric bounded domain that we model using a pseudo-spectral differentiable solver, thereby enabling online learning. We examine three configurations, varying the geometry (between an exponential container and a spherical shell) and the rotation rate. Flow is driven by a prescribed analytical forcing, allowing for precise control over the energy injection scale and an exact estimate of the power input. We evaluate the accuracy of the online-trained SGS model against the reference direct numerical simulation using integral quantities and spectral diagnostics. In all configurations, we show that an SGS model trained on data spanning only one turnover time remains stable and accurate over integrations at least a hundred times longer than the training period. Moreover, we demonstrate the model's remarkable ability to reproduce slow processes occurring on time scales far exceeding the training duration, such as the inward drift of jets in the spherical shell. These results suggest a promising path towards developing SGS models for planetary and stellar interior dynamics, including dynamo processes.
Adjoint-based online learning of two-layer quasi-geostrophic baroclinic turbulence
Nov 21, 2024For reasons of computational constraint, most global ocean circulation models used for Earth System Modeling still rely on parameterizations of sub-grid processes, and limitations in these parameterizations affect the modeled ocean circulation and impact on predictive skill. An increasingly popular approach is to leverage machine learning approaches for parameterizations, regressing for a map between the resolved state and missing feedbacks in a fluid system as a supervised learning task. However, the learning is often performed in an `offline' fashion, without involving the underlying fluid dynamical model during the training stage. Here, we explore the `online' approach that involves the fluid dynamical model during the training stage for the learning of baroclinic turbulence and its parameterization, with reference to ocean eddy parameterization. Two online approaches are considered: a full adjoint-based online approach, related to traditional adjoint optimization approaches that require a `differentiable' dynamical model, and an approximately online approach that approximates the adjoint calculation and does not require a differentiable dynamical model. The online approaches are found to be generally more skillful and numerically stable than offline approaches. Others details relating to online training, such as window size, machine learning model set up and designs of the loss functions are detailed to aid in further explorations of the online training methodology for Earth System Modeling.
Gradient-free online learning of subgrid-scale dynamics with neural emulators
Nov 02, 2023



In this paper, we propose a generic algorithm to train machine learning-based subgrid parametrizations online, i.e., with $\textit{a posteriori}$ loss functions for non-differentiable numerical solvers. The proposed approach leverage neural emulators to train an approximation of the reduced state-space solver, which is then used to allows gradient propagation through temporal integration steps. The algorithm is able to recover most of the benefit of online strategies without having to compute the gradient of the original solver. It is demonstrated that training the neural emulator and parametrization components separately with respective loss quantities is necessary in order to minimize the propagation of some approximation bias.
A posteriori learning for quasi-geostrophic turbulence parametrization
Apr 08, 2022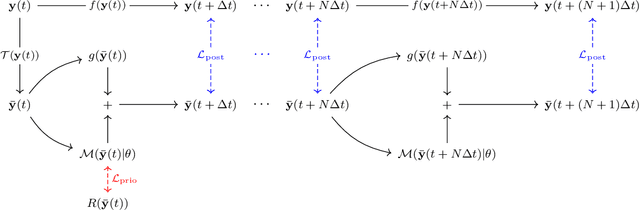

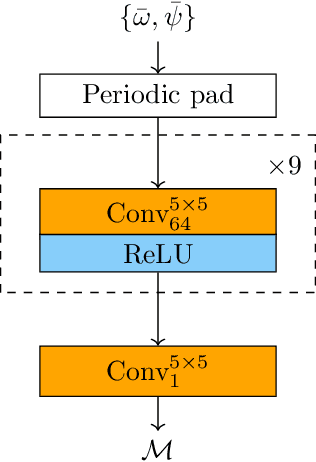
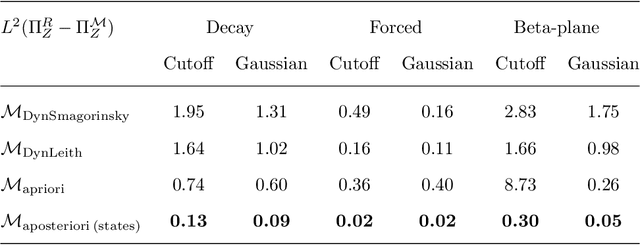
The use of machine learning to build subgrid parametrizations for climate models is receiving growing attention. State-of-the-art strategies address the problem as a supervised learning task and optimize algorithms that predict subgrid fluxes based on information from coarse resolution models. In practice, training data are generated from higher resolution numerical simulations transformed in order to mimic coarse resolution simulations. By essence, these strategies optimize subgrid parametrizations to meet so-called $\textit{a priori}$ criteria. But the actual purpose of a subgrid parametrization is to obtain good performance in terms of $\textit{a posteriori}$ metrics which imply computing entire model trajectories. In this paper, we focus on the representation of energy backscatter in two dimensional quasi-geostrophic turbulence and compare parametrizations obtained with different learning strategies at fixed computational complexity. We show that strategies based on $\textit{a priori}$ criteria yield parametrizations that tend to be unstable in direct simulations and describe how subgrid parametrizations can alternatively be trained end-to-end in order to meet $\textit{a posteriori}$ criteria. We illustrate that end-to-end learning strategies yield parametrizations that outperform known empirical and data-driven schemes in terms of performance, stability and ability to apply to different flow configurations. These results support the relevance of differentiable programming paradigms for climate models in the future.
A posteriori learning of quasi-geostrophic turbulence parametrization: an experiment on integration steps
Nov 27, 2021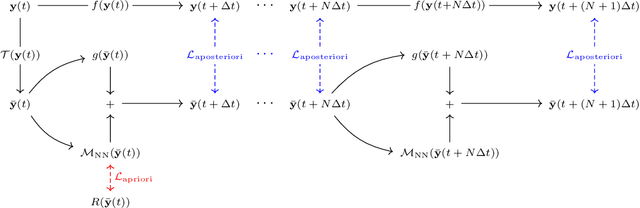


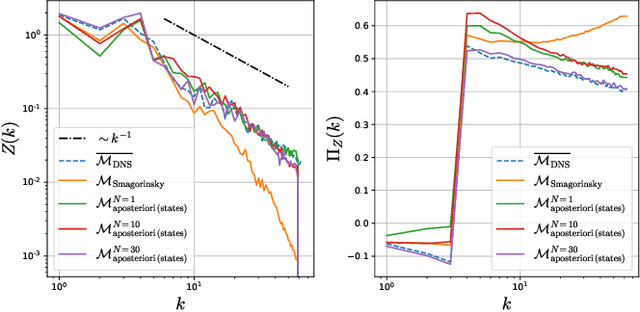
Modeling the subgrid-scale dynamics of reduced models is a long standing open problem that finds application in ocean, atmosphere and climate predictions where direct numerical simulation (DNS) is impossible. While neural networks (NNs) have already been applied to a range of three-dimensional flows with success, two dimensional flows are more challenging because of the backscatter of energy from small to large scales. We show that learning a model jointly with the dynamical solver and a meaningful \textit{a posteriori}-based loss function lead to stable and realistic simulations when applied to quasi-geostrophic turbulence.
Physical invariance in neural networks for subgrid-scale scalar flux modeling
Oct 09, 2020
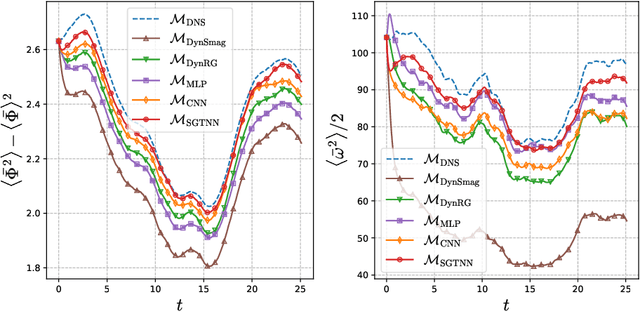
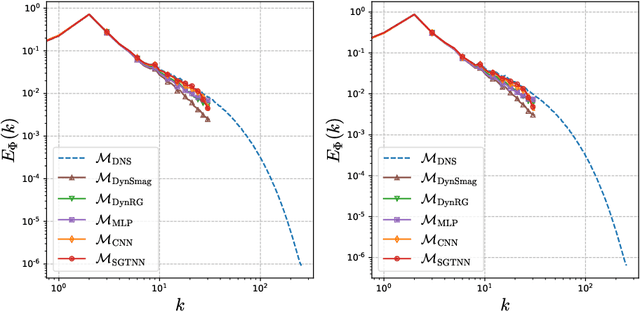
In this paper we present a new strategy to model the subgrid-scale scalar flux in a three-dimensional turbulent incompressible flow using physics-informed neural networks (NNs). When trained from direct numerical simulation (DNS) data, state-of-the-art neural networks, such as convolutional neural networks, may not preserve well known physical priors, which may in turn question their application to real case-studies. To address this issue, we investigate hard and soft constraints into the model based on classical invariances and symmetries derived from physical laws. From simulation-based experiments, we show that the proposed physically-invariant NN model outperforms both purely data-driven ones as well as parametric state-of-the-art subgrid-scale model. The considered invariances are regarded as regularizers on physical metrics during the a priori evaluation and constrain the distribution tails of the predicted subgrid-scale term to be closer to the DNS. They also increase the stability and performance of the model when used as a surrogate during a large-eddy simulation. Moreover, the physically-invariant NN is shown to generalize to configurations that have not been seen during the training phase.