Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation Learning by Reinforcement Learning
Paper and Code
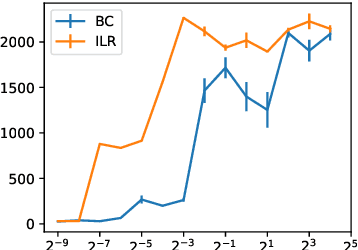
Imitation Learning algorithms learn a policy from demonstrations of expert behavior. Somewhat counterintuitively, we show that, for deterministic experts, imitation learning can be done by reduction to reinforcement learning, which is commonly considered more difficult. We conduct experiments which confirm that our reduction works well in practice for a continuous control task.
View paper on
 OpenReview
OpenReview