 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Model-free Reinforcement Learning with Multi-objective Bayesian Optimization
Paper and Code
Oct 29, 2019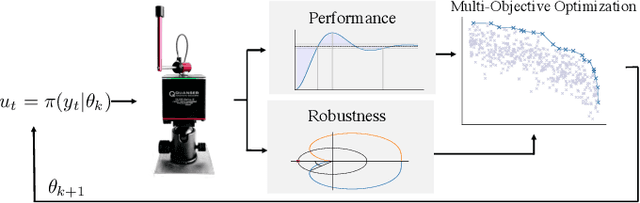
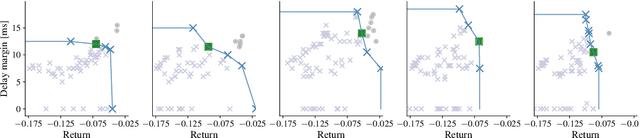
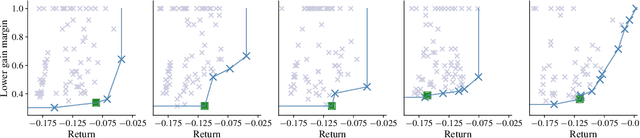

In reinforcement learning (RL), an autonomous agent learns to perform complex tasks by maximizing an exogenous reward signal while interacting with its environment. In real-world applications, test conditions may differ substantially from the training scenario and, therefore, focusing on pure reward maximization during training may lead to poor results at test time. In these cases, it is important to trade-off between performance and robustness while learning a policy. While several results exist for robust, model-based RL, the model-free case has not been widely investigated. In this paper, we cast the robust, model-free RL problem as a multi-objective optimization problem. To quantify the robustness of a policy, we use delay margin and gain margin, two robustness indicators that are common in control theory. We show how these metrics can be estimated from data in the model-free setting. We use multi-objective Bayesian optimization (MOBO) to solve efficiently this expensive-to-evaluate, multi-objective optimization problem. We show the benefits of our robust formulation both in sim-to-real and pure hardware experiments to balance a Furuta pendulum.