 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-ergodicity in reinforcement learning: robustness via ergodicity transformations
Oct 17, 2023Envisioned application areas for reinforcement learning (RL) include autonomous driving, precision agriculture, and finance, which all require RL agents to make decisions in the real world. A significant challenge hindering the adoption of RL methods in these domains is the non-robustness of conventional algorithms. In this paper, we argue that a fundamental issue contributing to this lack of robustness lies in the focus on the expected value of the return as the sole "correct" optimization objective. The expected value is the average over the statistical ensemble of infinitely many trajectories. For non-ergodic returns, this average differs from the average over a single but infinitely long trajectory. Consequently, optimizing the expected value can lead to policies that yield exceptionally high returns with probability zero but almost surely result in catastrophic outcomes. This problem can be circumvented by transforming the time series of collected returns into one with ergodic increments. This transformation enables learning robust policies by optimizing the long-term return for individual agents rather than the average across infinitely many trajectories. We propose an algorithm for learning ergodicity transformations from data and demonstrate its effectiveness in an instructive, non-ergodic environment and on standard RL benchmarks.
Distinguishing Risk Preferences using Repeated Gambles
Aug 14, 2023Sequences of repeated gambles provide an experimental tool to characterize the risk preferences of humans or artificial decision-making agents. The difficulty of this inference depends on factors including the details of the gambles offered and the number of iterations of the game played. In this paper we explore in detail the practical challenges of inferring risk preferences from the observed choices of artificial agents who are presented with finite sequences of repeated gambles. We are motivated by the fact that the strategy to maximize long-run wealth for sequences of repeated additive gambles (where gains and losses are independent of current wealth) is different to the strategy for repeated multiplicative gambles (where gains and losses are proportional to current wealth.) Accurate measurement of risk preferences would be needed to tell whether an agent is employing the optimal strategy or not. To generalize the types of gambles our agents face we use the Yeo-Johnson transformation, a tool borrowed from feature engineering for time series analysis, to construct a family of gambles that interpolates smoothly between the additive and multiplicative cases. We then analyze the optimal strategy for this family, both analytically and numerically. We find that it becomes increasingly difficult to distinguish the risk preferences of agents as their wealth increases. This is because agents with different risk preferences eventually make the same decisions for sufficiently high wealth. We believe that these findings are informative for the effective design of experiments to measure risk preferences in humans.
Forecasting new diseases in low-data settings using transfer learning
Apr 07, 2022



Recent infectious disease outbreaks, such as the COVID-19 pandemic and the Zika epidemic in Brazil, have demonstrated both the importance and difficulty of accurately forecasting novel infectious diseases. When new diseases first emerge, we have little knowledge of the transmission process, the level and duration of immunity to reinfection, or other parameters required to build realistic epidemiological models. Time series forecasts and machine learning, while less reliant on assumptions about the disease, require large amounts of data that are also not available in early stages of an outbreak. In this study, we examine how knowledge of related diseases can help make predictions of new diseases in data-scarce environments using transfer learning. We implement both an empirical and a theoretical approach. Using empirical data from Brazil, we compare how well different machine learning models transfer knowledge between two different disease pairs: (i) dengue and Zika, and (ii) influenza and COVID-19. In the theoretical analysis, we generate data using different transmission and recovery rates with an SIR compartmental model, and then compare the effectiveness of different transfer learning methods. We find that transfer learning offers the potential to improve predictions, even beyond a model based on data from the target disease, though the appropriate source disease must be chosen carefully. While imperfect, these models offer an additional input for decision makers during pandemic response.
Assessment of Reward Functions in Reinforcement Learning for Multi-Modal Urban Traffic Control under Real-World limitations
Oct 17, 2020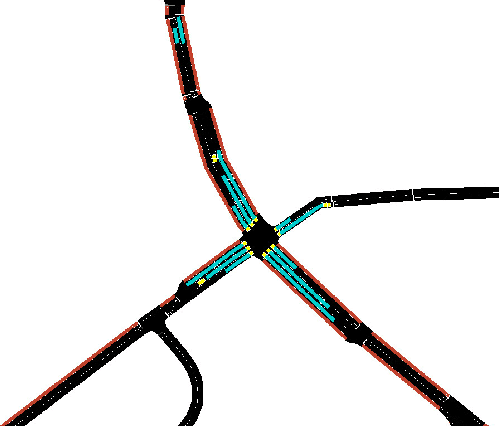

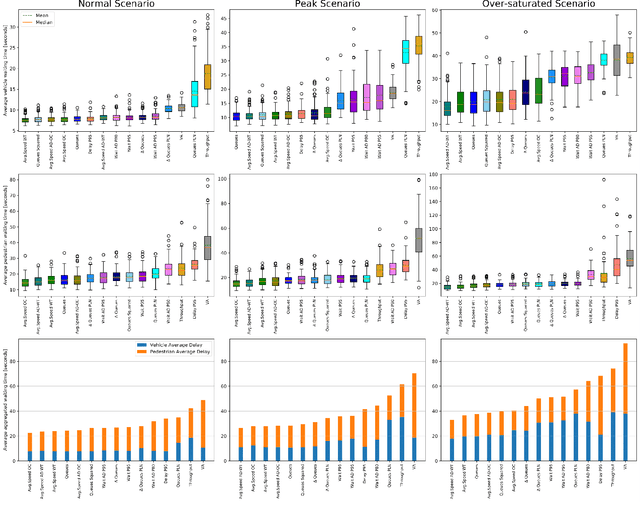

Reinforcement Learning is proving a successful tool that can manage urban intersections with a fraction of the effort required to curate traditional traffic controllers. However, literature on the introduction and control of pedestrians to such intersections is scarce. Furthermore, it is unclear what traffic state variables should be used as reward to obtain the best agent performance. This paper robustly evaluates 30 different Reinforcement Learning reward functions for controlling intersections serving pedestrians and vehicles covering the main traffic state variables available via modern vision-based sensors. Some rewards proposed in previous literature solely for vehicular traffic are extended to pedestrians while new ones are introduced. We use a calibrated model in terms of demand, sensors, green times and other operational constraints of a real intersection in Greater Manchester, UK. The assessed rewards can be classified in 5 groups depending on the magnitudes used: queues, waiting time, delay, average speed and throughput in the junction. The performance of different agents, in terms of waiting time, is compared across different demand levels, from normal operation to saturation of traditional adaptive controllers. We find that those rewards maximising the speed of the network obtain the lowest waiting time for vehicles and pedestrians simultaneously, closely followed by queue minimisation, demonstrating better performance than other previously proposed methods.
Assessment of Reward Functions for Reinforcement Learning Traffic Signal Control under Real-World Limitations
Aug 26, 2020

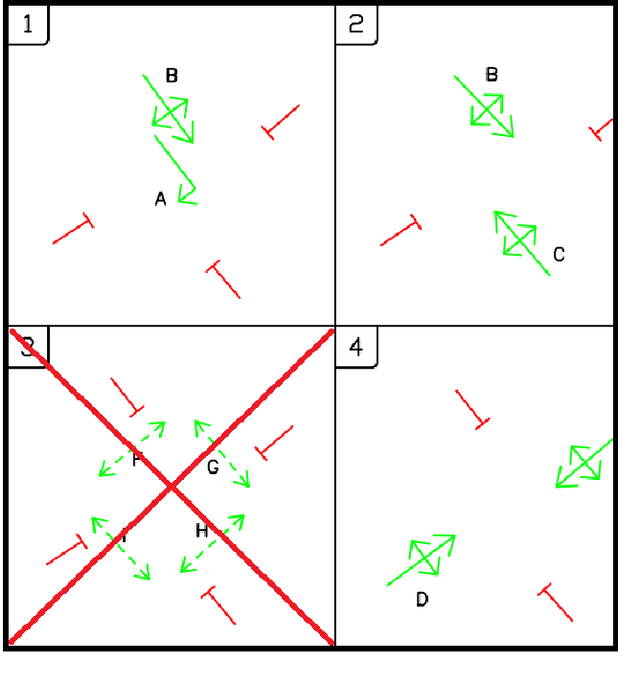
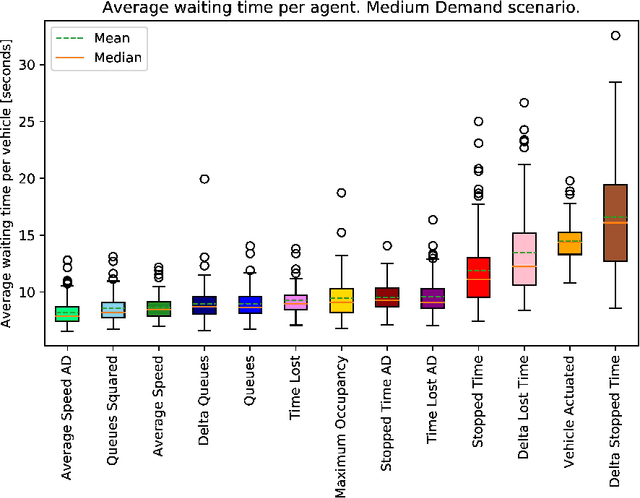
Adaptive traffic signal control is one key avenue for mitigating the growing consequences of traffic congestion. Incumbent solutions such as SCOOT and SCATS require regular and time-consuming calibration, can't optimise well for multiple road use modalities, and require the manual curation of many implementation plans. A recent alternative to these approaches are deep reinforcement learning algorithms, in which an agent learns how to take the most appropriate action for a given state of the system. This is guided by neural networks approximating a reward function that provides feedback to the agent regarding the performance of the actions taken, making it sensitive to the specific reward function chosen. Several authors have surveyed the reward functions used in the literature, but attributing outcome differences to reward function choice across works is problematic as there are many uncontrolled differences, as well as different outcome metrics. This paper compares the performance of agents using different reward functions in a simulation of a junction in Greater Manchester, UK, across various demand profiles, subject to real world constraints: realistic sensor inputs, controllers, calibrated demand, intergreen times and stage sequencing. The reward metrics considered are based on the time spent stopped, lost time, change in lost time, average speed, queue length, junction throughput and variations of these magnitudes. The performance of these reward functions is compared in terms of total waiting time. We find that speed maximisation resulted in the lowest average waiting times across all demand levels, displaying significantly better performance than other rewards previously introduced in the literature.