 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTune As You Scale: Hyperparameter Optimization For Compute Efficient Training
Jun 13, 2023Hyperparameter tuning of deep learning models can lead to order-of-magnitude performance gains for the same amount of compute. Despite this, systematic tuning is uncommon, particularly for large models, which are expensive to evaluate and tend to have many hyperparameters, necessitating difficult judgment calls about tradeoffs, budgets, and search bounds. To address these issues and propose a practical method for robustly tuning large models, we present Cost-Aware Pareto Region Bayesian Search (CARBS), a Bayesian optimization algorithm that performs local search around the performance-cost Pareto frontier. CARBS does well even in unbounded search spaces with many hyperparameters, learns scaling relationships so that it can tune models even as they are scaled up, and automates much of the "black magic" of tuning. Among our results, we effectively solve the entire ProcGen benchmark just by tuning a simple baseline (PPO, as provided in the original ProcGen paper). We also reproduce the model size vs. training tokens scaling result from the Chinchilla project (Hoffmann et al. 2022), while simultaneously discovering scaling laws for every other hyperparameter, via an easy automated process that uses significantly less compute and is applicable to any deep learning problem (not just language models).
On the stepwise nature of self-supervised learning
Mar 27, 2023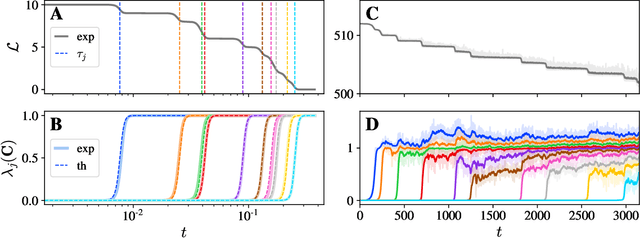
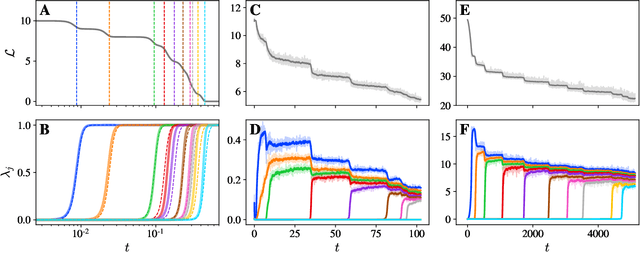
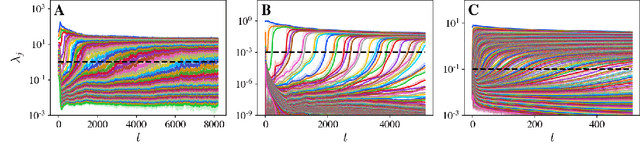
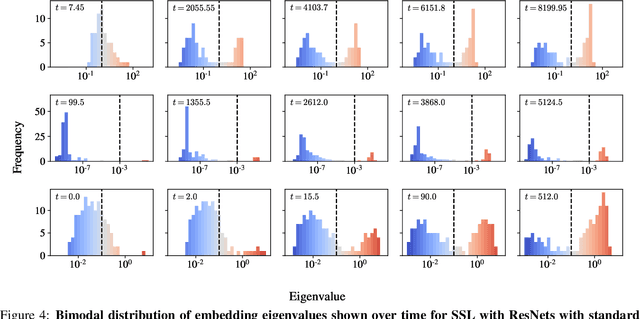
We present a simple picture of the training process of self-supervised learning methods with joint embedding networks. We find that these methods learn their high-dimensional embeddings one dimension at a time in a sequence of discrete, well-separated steps. We arrive at this conclusion via the study of a linearized model of Barlow Twins applicable to the case in which the trained network is infinitely wide. We solve the training dynamics of this model from small initialization, finding that the model learns the top eigenmodes of a certain contrastive kernel in a stepwise fashion, and obtain a closed-form expression for the final learned representations. Remarkably, we then see the same stepwise learning phenomenon when training deep ResNets using the Barlow Twins, SimCLR, and VICReg losses. Our theory suggests that, just as kernel regression can be thought of as a model of supervised learning, \textit{kernel PCA} may serve as a useful model of self-supervised learning.
Avalon: A Benchmark for RL Generalization Using Procedurally Generated Worlds
Oct 24, 2022



Despite impressive successes, deep reinforcement learning (RL) systems still fall short of human performance on generalization to new tasks and environments that differ from their training. As a benchmark tailored for studying RL generalization, we introduce Avalon, a set of tasks in which embodied agents in highly diverse procedural 3D worlds must survive by navigating terrain, hunting or gathering food, and avoiding hazards. Avalon is unique among existing RL benchmarks in that the reward function, world dynamics, and action space are the same for every task, with tasks differentiated solely by altering the environment; its 20 tasks, ranging in complexity from eat and throw to hunt and navigate, each create worlds in which the agent must perform specific skills in order to survive. This setup enables investigations of generalization within tasks, between tasks, and to compositional tasks that require combining skills learned from previous tasks. Avalon includes a highly efficient simulator, a library of baselines, and a benchmark with scoring metrics evaluated against hundreds of hours of human performance, all of which are open-source and publicly available. We find that standard RL baselines make progress on most tasks but are still far from human performance, suggesting Avalon is challenging enough to advance the quest for generalizable RL.
Assessment of Reward Functions for Reinforcement Learning Traffic Signal Control under Real-World Limitations
Aug 26, 2020

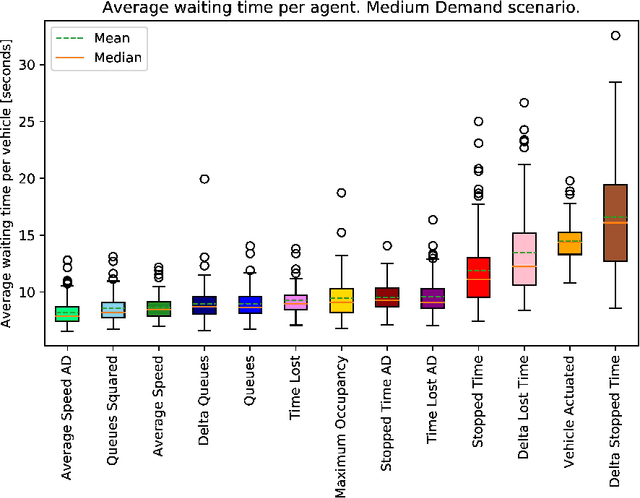
Adaptive traffic signal control is one key avenue for mitigating the growing consequences of traffic congestion. Incumbent solutions such as SCOOT and SCATS require regular and time-consuming calibration, can't optimise well for multiple road use modalities, and require the manual curation of many implementation plans. A recent alternative to these approaches are deep reinforcement learning algorithms, in which an agent learns how to take the most appropriate action for a given state of the system. This is guided by neural networks approximating a reward function that provides feedback to the agent regarding the performance of the actions taken, making it sensitive to the specific reward function chosen. Several authors have surveyed the reward functions used in the literature, but attributing outcome differences to reward function choice across works is problematic as there are many uncontrolled differences, as well as different outcome metrics. This paper compares the performance of agents using different reward functions in a simulation of a junction in Greater Manchester, UK, across various demand profiles, subject to real world constraints: realistic sensor inputs, controllers, calibrated demand, intergreen times and stage sequencing. The reward metrics considered are based on the time spent stopped, lost time, change in lost time, average speed, queue length, junction throughput and variations of these magnitudes. The performance of these reward functions is compared in terms of total waiting time. We find that speed maximisation resulted in the lowest average waiting times across all demand levels, displaying significantly better performance than other rewards previously introduced in the literature.