 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the stepwise nature of self-supervised learning
Paper and Code
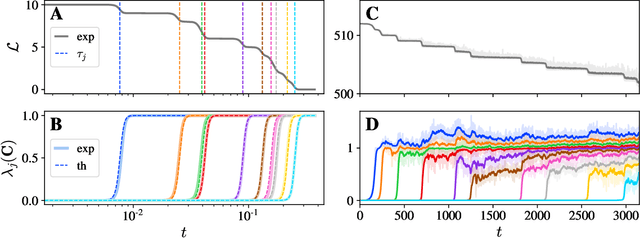
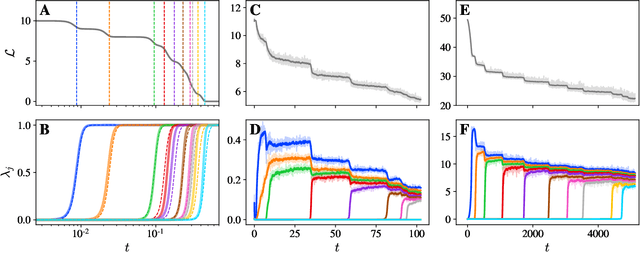
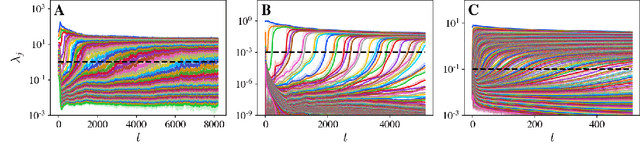
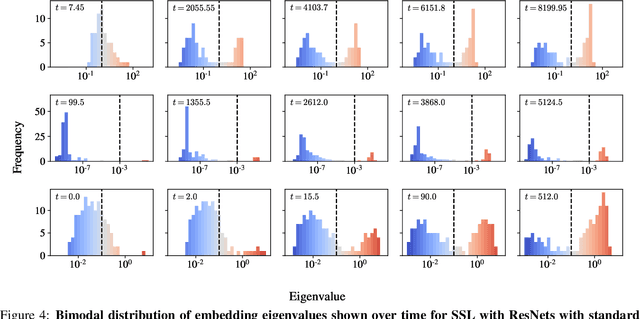
We present a simple picture of the training process of self-supervised learning methods with joint embedding networks. We find that these methods learn their high-dimensional embeddings one dimension at a time in a sequence of discrete, well-separated steps. We arrive at this conclusion via the study of a linearized model of Barlow Twins applicable to the case in which the trained network is infinitely wide. We solve the training dynamics of this model from small initialization, finding that the model learns the top eigenmodes of a certain contrastive kernel in a stepwise fashion, and obtain a closed-form expression for the final learned representations. Remarkably, we then see the same stepwise learning phenomenon when training deep ResNets using the Barlow Twins, SimCLR, and VICReg losses. Our theory suggests that, just as kernel regression can be thought of as a model of supervised learning, \textit{kernel PCA} may serve as a useful model of self-supervised learning.