 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Traffic Signal Control: Comparison with Commercial Systems
Apr 30, 2021
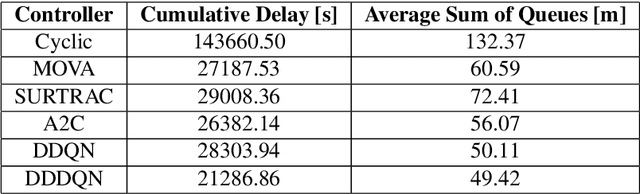

Recently, Intelligent Transportation Systems are leveraging the power of increased sensory coverage and computing power to deliver data-intensive solutions achieving higher levels of performance than traditional systems. Within Traffic Signal Control (TSC), this has allowed the emergence of Machine Learning (ML) based systems. Among this group, Reinforcement Learning (RL) approaches have performed particularly well. Given the lack of industry standards in ML for TSC, literature exploring RL often lacks comparison against commercially available systems and straightforward formulations of how the agents operate. Here we attempt to bridge that gap. We propose three different architectures for TSC RL agents and compare them against the currently used commercial systems MOVA, SurTrac and Cyclic controllers and provide pseudo-code for them. The agents use variations of Deep Q-Learning and Actor Critic, using states and rewards based on queue lengths. Their performance is compared in across different map scenarios with variable demand, assessing them in terms of the global delay and average queue length. We find that the RL-based systems can significantly and consistently achieve lower delays when compared with existing commercial systems.
Assessment of Reward Functions in Reinforcement Learning for Multi-Modal Urban Traffic Control under Real-World limitations
Oct 17, 2020

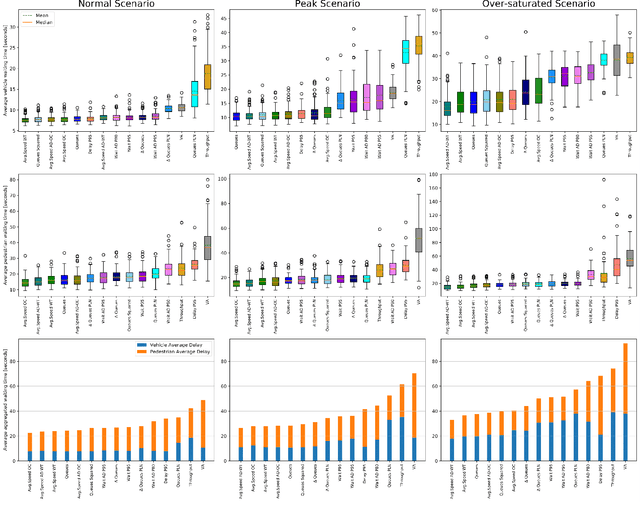

Reinforcement Learning is proving a successful tool that can manage urban intersections with a fraction of the effort required to curate traditional traffic controllers. However, literature on the introduction and control of pedestrians to such intersections is scarce. Furthermore, it is unclear what traffic state variables should be used as reward to obtain the best agent performance. This paper robustly evaluates 30 different Reinforcement Learning reward functions for controlling intersections serving pedestrians and vehicles covering the main traffic state variables available via modern vision-based sensors. Some rewards proposed in previous literature solely for vehicular traffic are extended to pedestrians while new ones are introduced. We use a calibrated model in terms of demand, sensors, green times and other operational constraints of a real intersection in Greater Manchester, UK. The assessed rewards can be classified in 5 groups depending on the magnitudes used: queues, waiting time, delay, average speed and throughput in the junction. The performance of different agents, in terms of waiting time, is compared across different demand levels, from normal operation to saturation of traditional adaptive controllers. We find that those rewards maximising the speed of the network obtain the lowest waiting time for vehicles and pedestrians simultaneously, closely followed by queue minimisation, demonstrating better performance than other previously proposed methods.
Assessment of Reward Functions for Reinforcement Learning Traffic Signal Control under Real-World Limitations
Aug 26, 2020

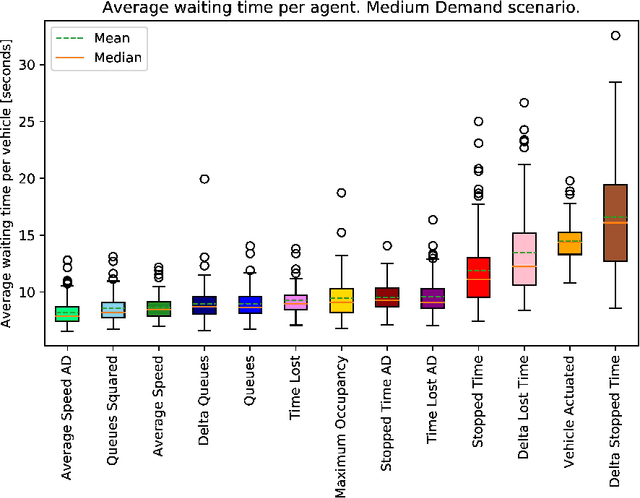
Adaptive traffic signal control is one key avenue for mitigating the growing consequences of traffic congestion. Incumbent solutions such as SCOOT and SCATS require regular and time-consuming calibration, can't optimise well for multiple road use modalities, and require the manual curation of many implementation plans. A recent alternative to these approaches are deep reinforcement learning algorithms, in which an agent learns how to take the most appropriate action for a given state of the system. This is guided by neural networks approximating a reward function that provides feedback to the agent regarding the performance of the actions taken, making it sensitive to the specific reward function chosen. Several authors have surveyed the reward functions used in the literature, but attributing outcome differences to reward function choice across works is problematic as there are many uncontrolled differences, as well as different outcome metrics. This paper compares the performance of agents using different reward functions in a simulation of a junction in Greater Manchester, UK, across various demand profiles, subject to real world constraints: realistic sensor inputs, controllers, calibrated demand, intergreen times and stage sequencing. The reward metrics considered are based on the time spent stopped, lost time, change in lost time, average speed, queue length, junction throughput and variations of these magnitudes. The performance of these reward functions is compared in terms of total waiting time. We find that speed maximisation resulted in the lowest average waiting times across all demand levels, displaying significantly better performance than other rewards previously introduced in the literature.