Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel-free Reinforcement Learning for Robust Locomotion Using Trajectory Optimization for Exploration
Paper and Code
Jul 14, 2021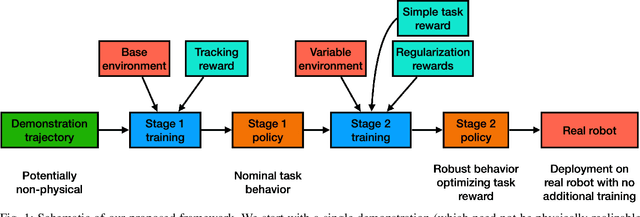

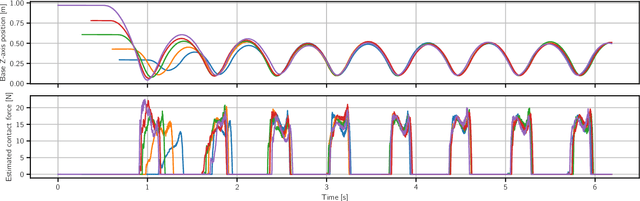
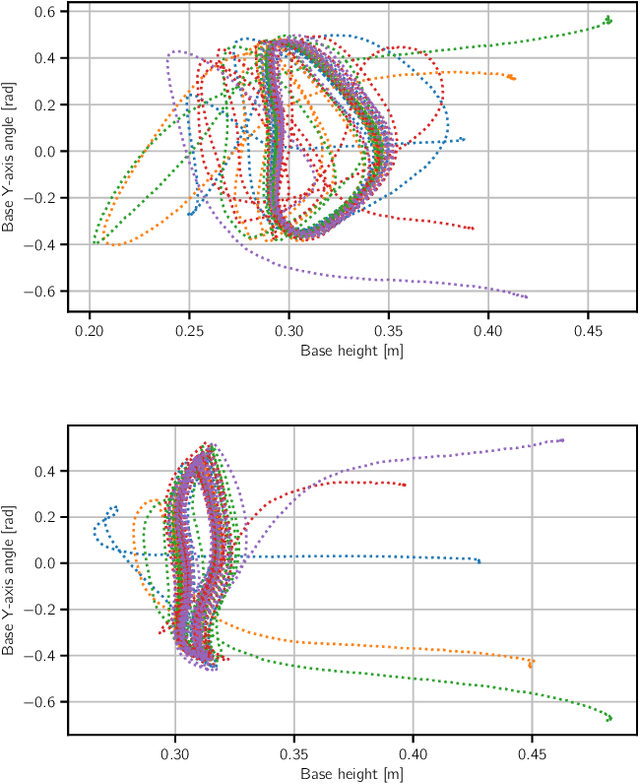
In this work we present a general, two-stage reinforcement learning approach for going from a single demonstration trajectory to a robust policy that can be deployed on hardware without any additional training. The demonstration is used in the first stage as a starting point to facilitate initial exploration. In the second stage, the relevant task reward is optimized directly and a policy robust to environment uncertainties is computed. We demonstrate and examine in detail performance and robustness of our approach on highly dynamic hopping and bounding tasks on a real quadruped robot.
View paper on