 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Guided Play: A Scheduled Hierarchical Approach for Improving Exploration in Adversarial Imitation Learning
Paper and Code
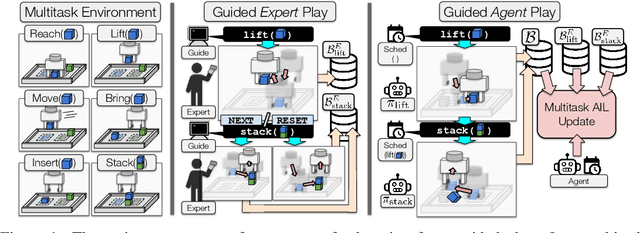
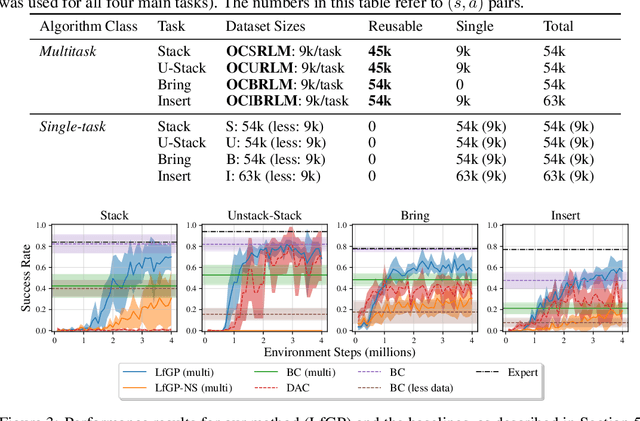

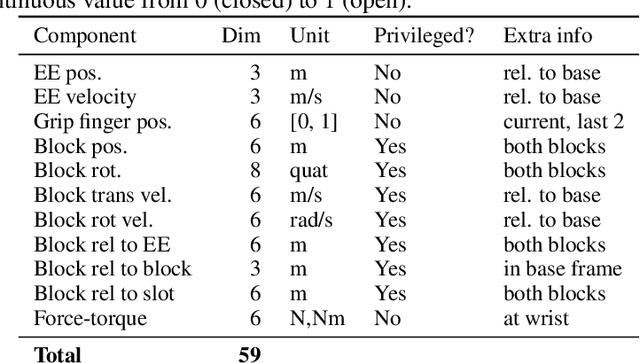
Effective exploration continues to be a significant challenge that prevents the deployment of reinforcement learning for many physical systems. This is particularly true for systems with continuous and high-dimensional state and action spaces, such as robotic manipulators. The challenge is accentuated in the sparse rewards setting, where the low-level state information required for the design of dense rewards is unavailable. Adversarial imitation learning (AIL) can partially overcome this barrier by leveraging expert-generated demonstrations of optimal behaviour and providing, essentially, a replacement for dense reward information. Unfortunately, the availability of expert demonstrations does not necessarily improve an agent's capability to explore effectively and, as we empirically show, can lead to inefficient or stagnated learning. We present Learning from Guided Play (LfGP), a framework in which we leverage expert demonstrations of, in addition to a main task, multiple auxiliary tasks. Subsequently, a hierarchical model is used to learn each task reward and policy through a modified AIL procedure, in which exploration of all tasks is enforced via a scheduler composing different tasks together. This affords many benefits: learning efficiency is improved for main tasks with challenging bottleneck transitions, expert data becomes reusable between tasks, and transfer learning through the reuse of learned auxiliary task models becomes possible. Our experimental results in a challenging multitask robotic manipulation domain indicate that our method compares favourably to supervised imitation learning and to a state-of-the-art AIL method. Code is available at https://github.com/utiasSTARS/lfgp.