 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble of LSTMs and feature selection for human action prediction
Paper and Code

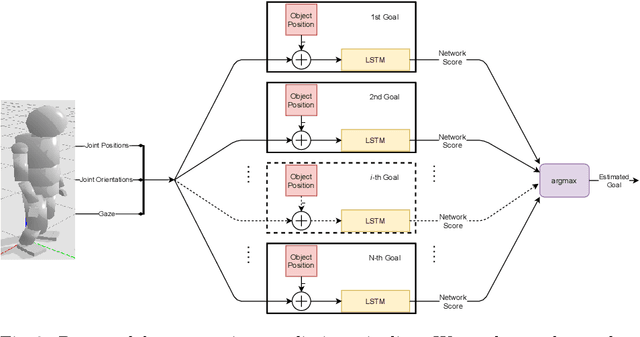
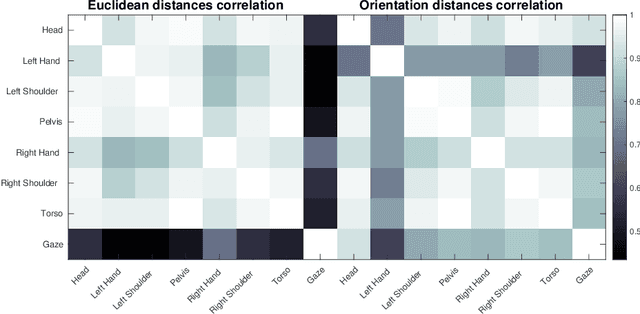
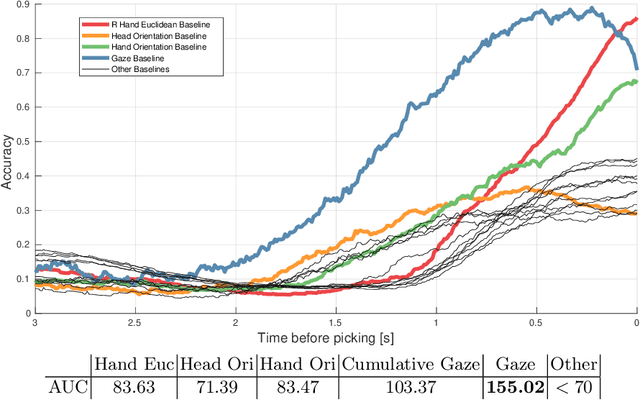
As robots are becoming more and more ubiquitous in human environments, it will be necessary for robotic systems to better understand and predict human actions. However, this is not an easy task, at times not even for us humans, but based on a relatively structured set of possible actions, appropriate cues, and the right model, this problem can be computationally tackled. In this paper, we propose to use an ensemble of long-short term memory (LSTM) networks for human action prediction. To train and evaluate models, we used the MoGaze dataset - currently the most comprehensive dataset capturing poses of human joints and the human gaze. We have thoroughly analyzed the MoGaze dataset and selected a reduced set of cues for this task. Our model can predict (i) which of the labeled objects the human is going to grasp, and (ii) which of the macro locations the human is going to visit (such as table or shelf). We have exhaustively evaluated the proposed method and compared it to individual cue baselines. The results suggest that our LSTM model slightly outperforms the gaze baseline in single object picking accuracy, but achieves better accuracy in macro object prediction. Furthermore, we have also analyzed the prediction accuracy when the gaze is not used, and in this case, the LSTM model considerably outperformed the best single cue baseline