 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal semantic forecasting based on conditional generation of future features
Paper and Code
Oct 18, 2020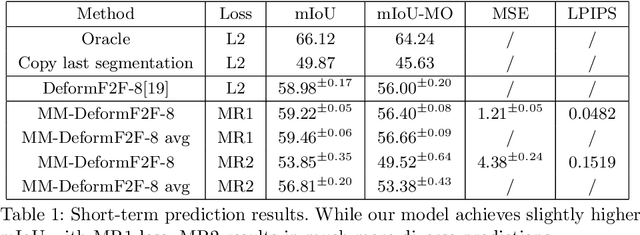

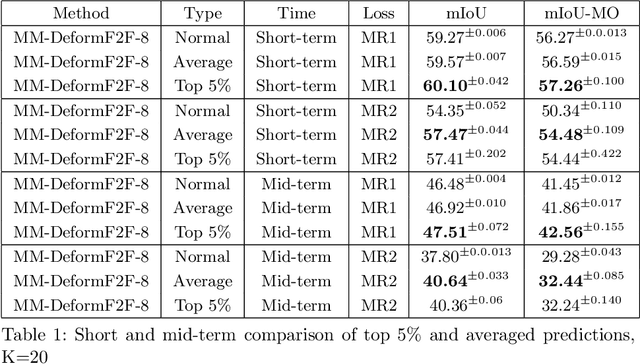
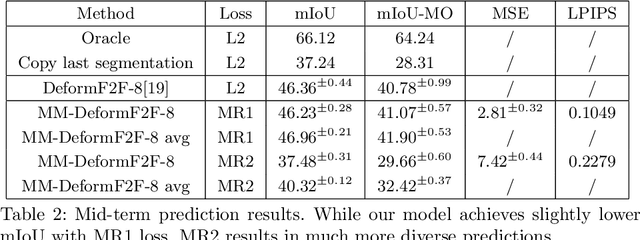
This paper considers semantic forecasting in road-driving scenes. Most existing approaches address this problem as deterministic regression of future features or future predictions given observed frames. However, such approaches ignore the fact that future can not always be guessed with certainty. For example, when a car is about to turn around a corner, the road which is currently occluded by buildings may turn out to be either free to drive, or occupied by people, other vehicles or roadworks. When a deterministic model confronts such situation, its best guess is to forecast the most likely outcome. However, this is not acceptable since it defeats the purpose of forecasting to improve security. It also throws away valuable training data, since a deterministic model is unable to learn any deviation from the norm. We address this problem by providing more freedom to the model through allowing it to forecast different futures. We propose to formulate multimodal forecasting as sampling of a multimodal generative model conditioned on the observed frames. Experiments on the Cityscapes dataset reveal that our multimodal model outperforms its deterministic counterpart in short-term forecasting while performing slightly worse in the mid-term case.