 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic loss balancing and sequential enhancement for road-safety assessment and traffic scene classification
Nov 08, 2022



Road-safety inspection is an indispensable instrument for reducing road-accident fatalities contributed to road infrastructure. Recent work formalizes road-safety assessment in terms of carefully selected risk factors that are also known as road-safety attributes. In current practice, these attributes are manually annotated in geo-referenced monocular video for each road segment. We propose to reduce dependency on tedious human labor by automating recognition with a two-stage neural architecture. The first stage predicts more than forty road-safety attributes by observing a local spatio-temporal context. Our design leverages an efficient convolutional pipeline, which benefits from pre-training on semantic segmentation of street scenes. The second stage enhances predictions through sequential integration across a larger temporal window. Our design leverages per-attribute instances of a lightweight bidirectional LSTM architecture. Both stages alleviate extreme class imbalance by incorporating a multi-task variant of recall-based dynamic loss weighting. We perform experiments on the iRAP-BH dataset, which involves fully labeled geo-referenced video along 2,300 km of public roads in Bosnia and Herzegovina. We also validate our approach by comparing it with the related work on two road-scene classification datasets from the literature: Honda Scenes and FM3m. Experimental evaluation confirms the value of our contributions on all three datasets.
A Novel Georeferenced Dataset for Stereo Visual Odometry
Oct 01, 2013
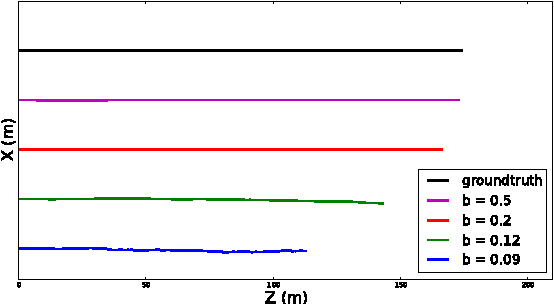
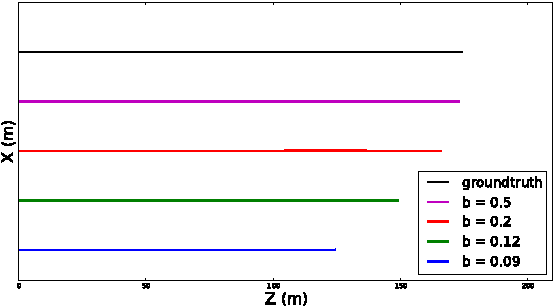
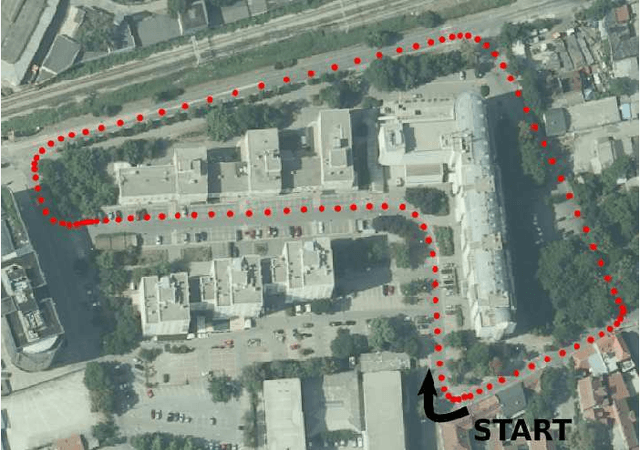
In this work, we present a novel dataset for assessing the accuracy of stereo visual odometry. The dataset has been acquired by a small-baseline stereo rig mounted on the top of a moving car. The groundtruth is supplied by a consumer grade GPS device without IMU. Synchronization and alignment between GPS readings and stereo frames are recovered after the acquisition. We show that the attained groundtruth accuracy allows to draw useful conclusions in practice. The presented experiments address influence of camera calibration, baseline distance and zero-disparity features to the achieved reconstruction performance.