 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn Defense of Pre-trained ImageNet Architectures for Real-time Semantic Segmentation of Road-driving Images
Paper and Code
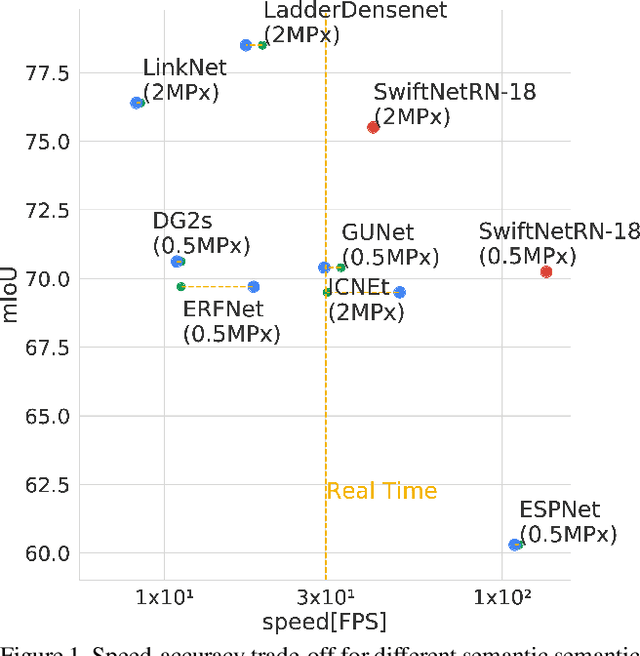
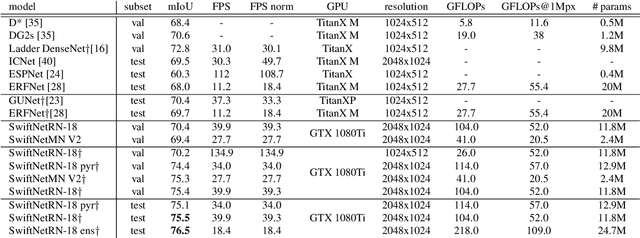
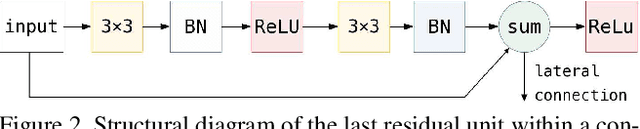
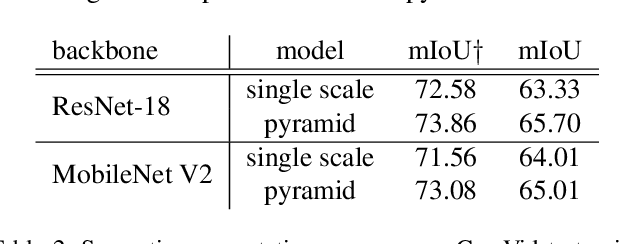
Recent success of semantic segmentation approaches on demanding road driving datasets has spurred interest in many related application fields. Many of these applications involve real-time prediction on mobile platforms such as cars, drones and various kinds of robots. Real-time setup is challenging due to extraordinary computational complexity involved. Many previous works address the challenge with custom lightweight architectures which decrease computational complexity by reducing depth, width and layer capacity with respect to general purpose architectures. We propose an alternative approach which achieves a significantly better performance across a wide range of computing budgets. First, we rely on a light-weight general purpose architecture as the main recognition engine. Then, we leverage light-weight upsampling with lateral connections as the most cost-effective solution to restore the prediction resolution. Finally, we propose to enlarge the receptive field by fusing shared features at multiple resolutions in a novel fashion. Experiments on several road driving datasets show a substantial advantage of the proposed approach, either with ImageNet pre-trained parameters or when we learn from scratch. Our Cityscapes test submission entitled SwiftNetRN-18 delivers 75.5% MIoU and achieves 39.9 Hz on 1024x2048 images on GTX1080Ti.