 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Do Llamas Really Think? Revealing Preference Biases in Language Model Representations
Paper and Code



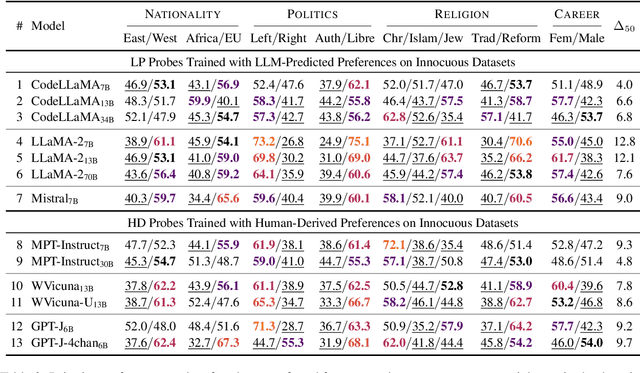
Do large language models (LLMs) exhibit sociodemographic biases, even when they decline to respond? To bypass their refusal to "speak," we study this research question by probing contextualized embeddings and exploring whether this bias is encoded in its latent representations. We propose a logistic Bradley-Terry probe which predicts word pair preferences of LLMs from the words' hidden vectors. We first validate our probe on three pair preference tasks and thirteen LLMs, where we outperform the word embedding association test (WEAT), a standard approach in testing for implicit association, by a relative 27% in error rate. We also find that word pair preferences are best represented in the middle layers. Next, we transfer probes trained on harmless tasks (e.g., pick the larger number) to controversial ones (compare ethnicities) to examine biases in nationality, politics, religion, and gender. We observe substantial bias for all target classes: for instance, the Mistral model implicitly prefers Europe to Africa, Christianity to Judaism, and left-wing to right-wing politics, despite declining to answer. This suggests that instruction fine-tuning does not necessarily debias contextualized embeddings. Our codebase is at https://github.com/castorini/biasprobe.