 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre We There Yet? A Decision Framework for Replacing Term Based Retrieval with Dense Retrieval Systems
Paper and Code
Jun 26, 2022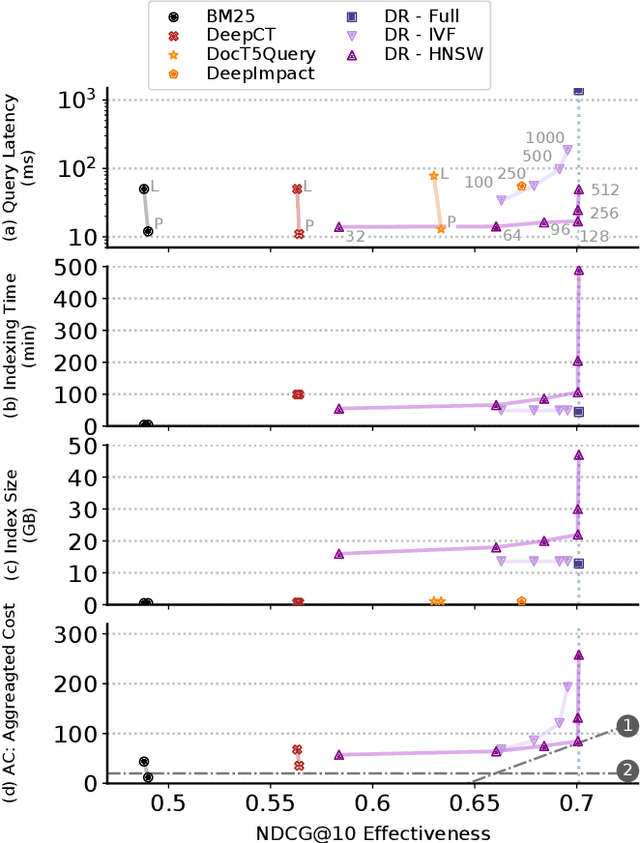
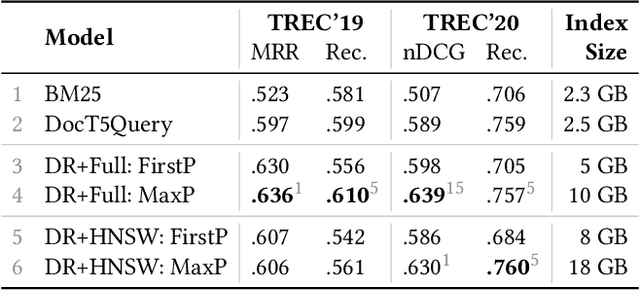

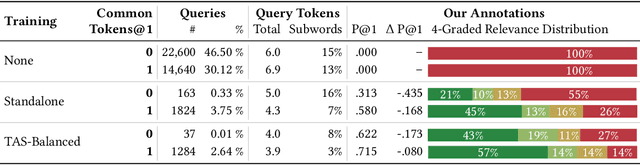
Recently, several dense retrieval (DR) models have demonstrated competitive performance to term-based retrieval that are ubiquitous in search systems. In contrast to term-based matching, DR projects queries and documents into a dense vector space and retrieves results via (approximate) nearest neighbor search. Deploying a new system, such as DR, inevitably involves tradeoffs in aspects of its performance. Established retrieval systems running at scale are usually well understood in terms of effectiveness and costs, such as query latency, indexing throughput, or storage requirements. In this work, we propose a framework with a set of criteria that go beyond simple effectiveness measures to thoroughly compare two retrieval systems with the explicit goal of assessing the readiness of one system to replace the other. This includes careful tradeoff considerations between effectiveness and various cost factors. Furthermore, we describe guardrail criteria, since even a system that is better on average may have systematic failures on a minority of queries. The guardrails check for failures on certain query characteristics and novel failure types that are only possible in dense retrieval systems. We demonstrate our decision framework on a Web ranking scenario. In that scenario, state-of-the-art DR models have surprisingly strong results, not only on average performance but passing an extensive set of guardrail tests, showing robustness on different query characteristics, lexical matching, generalization, and number of regressions. It is impossible to predict whether DR will become ubiquitous in the future, but one way this is possible is through repeated applications of decision processes such as the one presented here.