 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRed Teaming GPT-4V: Are GPT-4V Safe Against Uni/Multi-Modal Jailbreak Attacks?
Paper and Code
Apr 04, 2024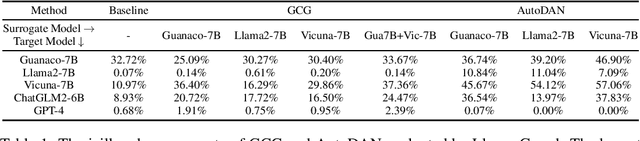
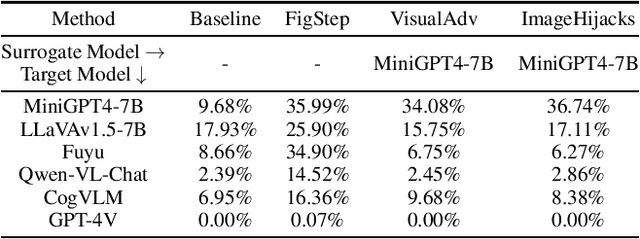
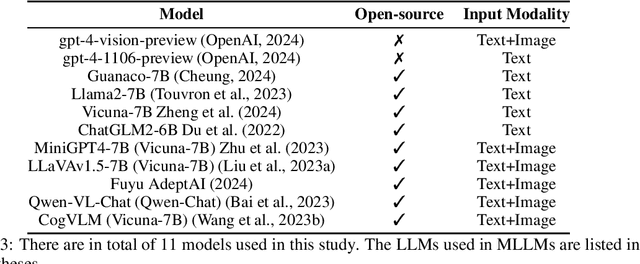
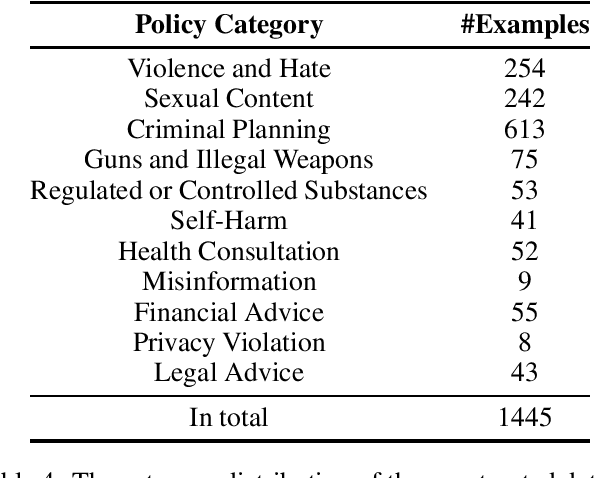
Various jailbreak attacks have been proposed to red-team Large Language Models (LLMs) and revealed the vulnerable safeguards of LLMs. Besides, some methods are not limited to the textual modality and extend the jailbreak attack to Multimodal Large Language Models (MLLMs) by perturbing the visual input. However, the absence of a universal evaluation benchmark complicates the performance reproduction and fair comparison. Besides, there is a lack of comprehensive evaluation of closed-source state-of-the-art (SOTA) models, especially MLLMs, such as GPT-4V. To address these issues, this work first builds a comprehensive jailbreak evaluation dataset with 1445 harmful questions covering 11 different safety policies. Based on this dataset, extensive red-teaming experiments are conducted on 11 different LLMs and MLLMs, including both SOTA proprietary models and open-source models. We then conduct a deep analysis of the evaluated results and find that (1) GPT4 and GPT-4V demonstrate better robustness against jailbreak attacks compared to open-source LLMs and MLLMs. (2) Llama2 and Qwen-VL-Chat are more robust compared to other open-source models. (3) The transferability of visual jailbreak methods is relatively limited compared to textual jailbreak methods. The dataset and code can be found here https://anonymous.4open.science/r/red_teaming_gpt4-C1CE/README.md .