 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Question Answering over Temporal Knowledge Graphs
Aug 12, 2022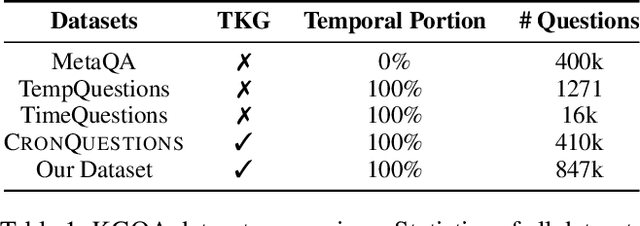

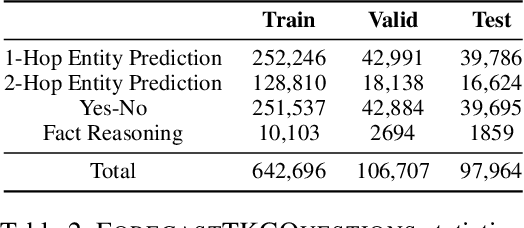
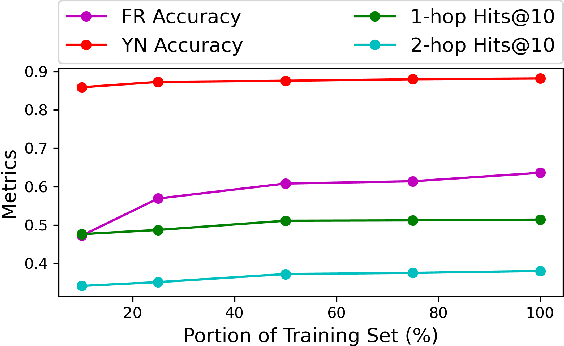
Question answering over temporal knowledge graphs (TKGQA) has recently found increasing interest. TKGQA requires temporal reasoning techniques to extract the relevant information from temporal knowledge bases. The only existing TKGQA dataset, i.e., CronQuestions, consists of temporal questions based on the facts from a fixed time period, where a temporal knowledge graph (TKG) spanning the same period can be fully used for answer inference, allowing the TKGQA models to use even the future knowledge to answer the questions based on the past facts. In real-world scenarios, however, it is also common that given the knowledge until now, we wish the TKGQA systems to answer the questions asking about the future. As humans constantly seek plans for the future, building TKGQA systems for answering such forecasting questions is important. Nevertheless, this has still been unexplored in previous research. In this paper, we propose a novel task: forecasting question answering over temporal knowledge graphs. We also propose a large-scale TKGQA benchmark dataset, i.e., ForecastTKGQuestions, for this task. It includes three types of questions, i.e., entity prediction, yes-no, and fact reasoning questions. For every forecasting question in our dataset, QA models can only have access to the TKG information before the timestamp annotated in the given question for answer inference. We find that the state-of-the-art TKGQA methods perform poorly on forecasting questions, and they are unable to answer yes-no questions and fact reasoning questions. To this end, we propose ForecastTKGQA, a TKGQA model that employs a TKG forecasting module for future inference, to answer all three types of questions. Experimental results show that ForecastTKGQA outperforms recent TKGQA methods on the entity prediction questions, and it also shows great effectiveness in answering the other two types of questions.
Argument Mining Driven Analysis of Peer-Reviews
Dec 10, 2020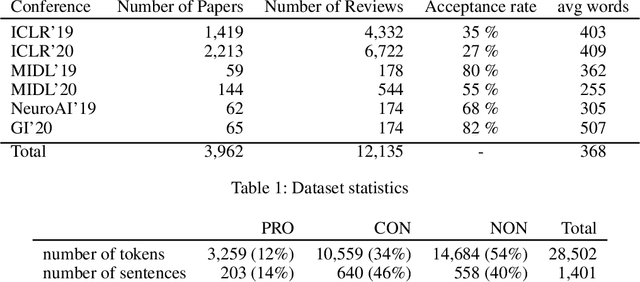
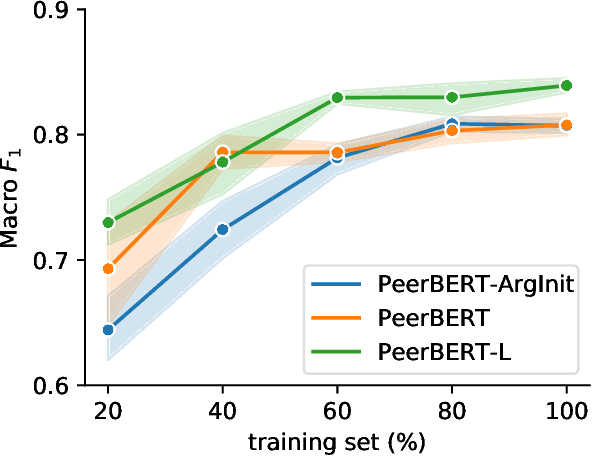

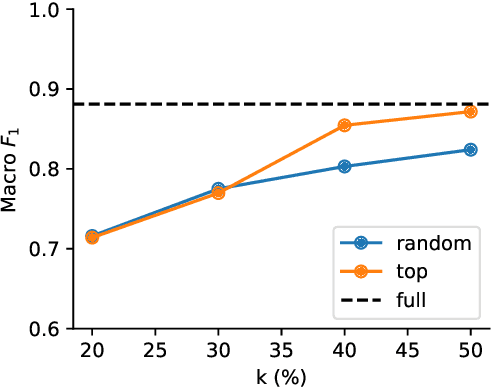
Peer reviewing is a central process in modern research and essential for ensuring high quality and reliability of published work. At the same time, it is a time-consuming process and increasing interest in emerging fields often results in a high review workload, especially for senior researchers in this area. How to cope with this problem is an open question and it is vividly discussed across all major conferences. In this work, we propose an Argument Mining based approach for the assistance of editors, meta-reviewers, and reviewers. We demonstrate that the decision process in the field of scientific publications is driven by arguments and automatic argument identification is helpful in various use-cases. One of our findings is that arguments used in the peer-review process differ from arguments in other domains making the transfer of pre-trained models difficult. Therefore, we provide the community with a new peer-review dataset from different computer science conferences with annotated arguments. In our extensive empirical evaluation, we show that Argument Mining can be used to efficiently extract the most relevant parts from reviews, which are paramount for the publication decision. The process remains interpretable since the extracted arguments can be highlighted in a review without detaching them from their context.