 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised learning for radio-astronomy source classification: a benchmark
Nov 22, 2024The upcoming Square Kilometer Array (SKA) telescope marks a significant step forward in radio astronomy, presenting new opportunities and challenges for data analysis. Traditional visual models pretrained on optical photography images may not perform optimally on radio interferometry images, which have distinct visual characteristics. Self-Supervised Learning (SSL) offers a promising approach to address this issue, leveraging the abundant unlabeled data in radio astronomy to train neural networks that learn useful representations from radio images. This study explores the application of SSL to radio astronomy, comparing the performance of SSL-trained models with that of traditional models pretrained on natural images, evaluating the importance of data curation for SSL, and assessing the potential benefits of self-supervision to different domain-specific radio astronomy datasets. Our results indicate that, SSL-trained models achieve significant improvements over the baseline in several downstream tasks, especially in the linear evaluation setting; when the entire backbone is fine-tuned, the benefits of SSL are less evident but still outperform pretraining. These findings suggest that SSL can play a valuable role in efficiently enhancing the analysis of radio astronomical data. The trained models and code is available at: \url{https://github.com/dr4thmos/solo-learn-radio}
RG-CAT: Detection Pipeline and Catalogue of Radio Galaxies in the EMU Pilot Survey
Mar 21, 2024We present source detection and catalogue construction pipelines to build the first catalogue of radio galaxies from the 270 $\rm deg^2$ pilot survey of the Evolutionary Map of the Universe (EMU-PS) conducted with the Australian Square Kilometre Array Pathfinder (ASKAP) telescope. The detection pipeline uses Gal-DINO computer-vision networks (Gupta et al., 2024) to predict the categories of radio morphology and bounding boxes for radio sources, as well as their potential infrared host positions. The Gal-DINO network is trained and evaluated on approximately 5,000 visually inspected radio galaxies and their infrared hosts, encompassing both compact and extended radio morphologies. We find that the Intersection over Union (IoU) for the predicted and ground truth bounding boxes is larger than 0.5 for 99% of the radio sources, and 98% of predicted host positions are within $3^{\prime \prime}$ of the ground truth infrared host in the evaluation set. The catalogue construction pipeline uses the predictions of the trained network on the radio and infrared image cutouts based on the catalogue of radio components identified using the Selavy source finder algorithm. Confidence scores of the predictions are then used to prioritize Selavy components with higher scores and incorporate them first into the catalogue. This results in identifications for a total of 211,625 radio sources, with 201,211 classified as compact and unresolved. The remaining 10,414 are categorized as extended radio morphologies, including 582 FR-I, 5,602 FR-II, 1,494 FR-x (uncertain whether FR-I or FR-II), 2,375 R (single-peak resolved) radio galaxies, and 361 with peculiar and other rare morphologies. We cross-match the radio sources in the catalogue with the infrared and optical catalogues, finding infrared cross-matches for 73% and photometric redshifts for 36% of the radio galaxies.
RADiff: Controllable Diffusion Models for Radio Astronomical Maps Generation
Jul 05, 2023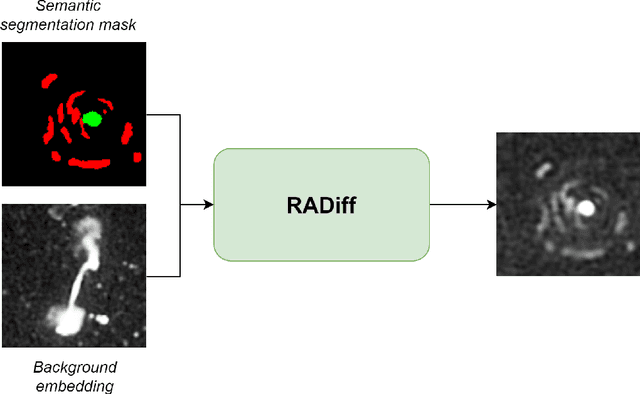
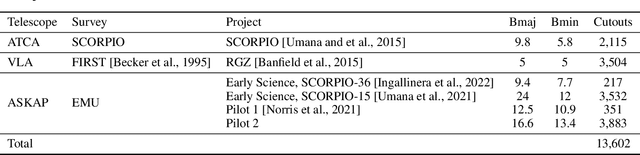
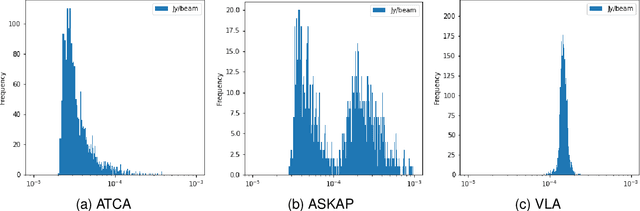
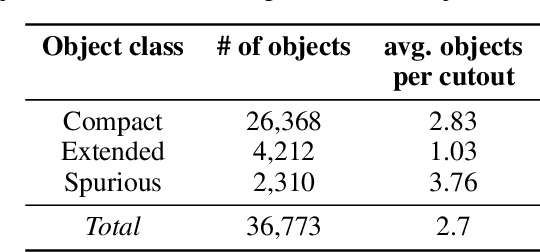
Along with the nearing completion of the Square Kilometre Array (SKA), comes an increasing demand for accurate and reliable automated solutions to extract valuable information from the vast amount of data it will allow acquiring. Automated source finding is a particularly important task in this context, as it enables the detection and classification of astronomical objects. Deep-learning-based object detection and semantic segmentation models have proven to be suitable for this purpose. However, training such deep networks requires a high volume of labeled data, which is not trivial to obtain in the context of radio astronomy. Since data needs to be manually labeled by experts, this process is not scalable to large dataset sizes, limiting the possibilities of leveraging deep networks to address several tasks. In this work, we propose RADiff, a generative approach based on conditional diffusion models trained over an annotated radio dataset to generate synthetic images, containing radio sources of different morphologies, to augment existing datasets and reduce the problems caused by class imbalances. We also show that it is possible to generate fully-synthetic image-annotation pairs to automatically augment any annotated dataset. We evaluate the effectiveness of this approach by training a semantic segmentation model on a real dataset augmented in two ways: 1) using synthetic images obtained from real masks, and 2) generating images from synthetic semantic masks. We show an improvement in performance when applying augmentation, gaining up to 18% in performance when using real masks and 4% when augmenting with synthetic masks. Finally, we employ this model to generate large-scale radio maps with the objective of simulating Data Challenges.
Radio astronomical images object detection and segmentation: A benchmark on deep learning methods
Mar 08, 2023In recent years, deep learning has been successfully applied in various scientific domains. Following these promising results and performances, it has recently also started being evaluated in the domain of radio astronomy. In particular, since radio astronomy is entering the Big Data era, with the advent of the largest telescope in the world - the Square Kilometre Array (SKA), the task of automatic object detection and instance segmentation is crucial for source finding and analysis. In this work, we explore the performance of the most affirmed deep learning approaches, applied to astronomical images obtained by radio interferometric instrumentation, to solve the task of automatic source detection. This is carried out by applying models designed to accomplish two different kinds of tasks: object detection and semantic segmentation. The goal is to provide an overview of existing techniques, in terms of prediction performance and computational efficiency, to scientists in the astrophysics community who would like to employ machine learning in their research.
A Comparative Study of Convolutional Neural Networks for the Detection of Strong Gravitational Lensing
Jun 03, 2021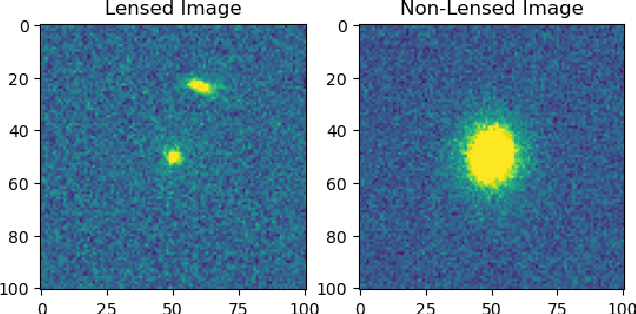
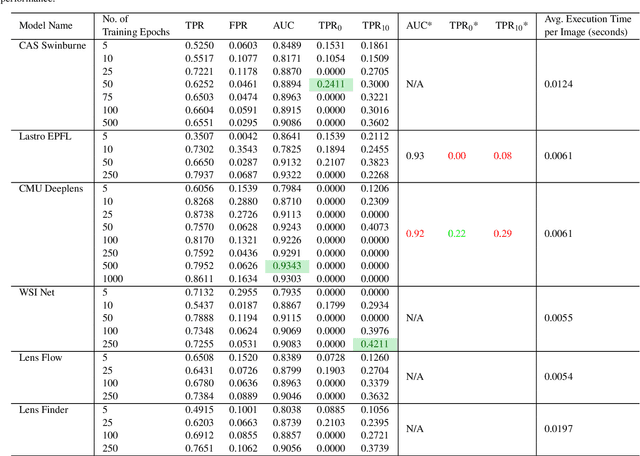
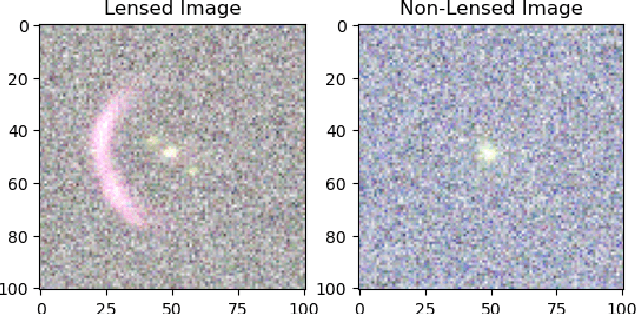
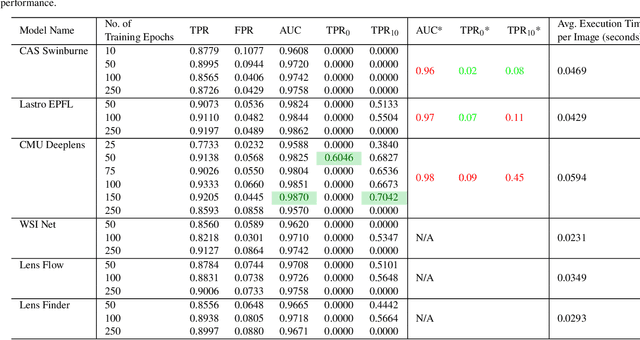
As we enter the era of large-scale imaging surveys with the up-coming telescopes such as LSST and SKA, it is envisaged that the number of known strong gravitational lensing systems will increase dramatically. However, these events are still very rare and require the efficient processing of millions of images. In order to tackle this image processing problem, we present Machine Learning techniques and apply them to the Gravitational Lens Finding Challenge. The Convolutional Neural Networks (CNNs) presented have been re-implemented within a new modular, and extendable framework, LEXACTUM. We report an Area Under the Curve (AUC) of 0.9343 and 0.9870, and an execution time of 0.0061s and 0.0594s per image, for the Space and Ground datasets respectively, showing that the results obtained by CNNs are very competitive with conventional methods (such as visual inspection and arc finders) for detecting gravitational lenses.