 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Critical Look At The Identifiability of Causal Effects with Deep Latent Variable Models
Paper and Code
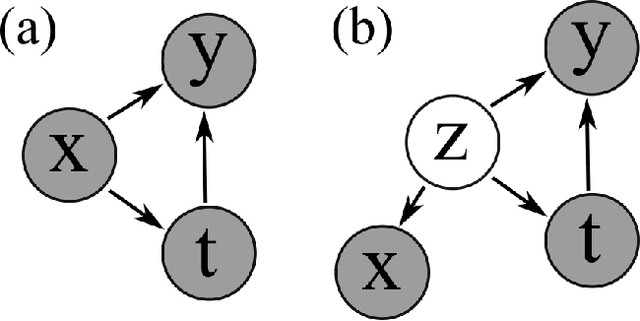


Using deep latent variable models in causal inference has attracted considerable interest recently, but an essential open question is their identifiability. While they have yielded promising results and theory exists on the identifiability of some simple model formulations, we also know that causal effects cannot be identified in general with latent variables. We investigate this gap between theory and empirical results with theoretical considerations and extensive experiments under multiple synthetic and real-world data sets, using the causal effect variational autoencoder (CEVAE) as a case study. While CEVAE seems to work reliably under some simple scenarios, it does not identify the correct causal effect with a misspecified latent variable or a complex data distribution, as opposed to the original goals of the model. Our results show that the question of identifiability cannot be disregarded, and we argue that more attention should be paid to it in future work.