 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMargin-calibrated Classifier Guidance for Property-driven Synthesis Planning
May 13, 2026Synthesis planning seeks an efficient sequence of chemical reactions that produce a target molecule. Typically, a pretrained single-step (autoregressive) retrosynthesis model is repeatedly invoked to generate such a sequence. Classifier guidance can, in principle, help steer the output of single-step model toward reactions that satisfy specific constraints or accommodate chemist's preferences during inference without having to retrain the autoregressive generator. We expose the insufficiency of auxiliary classifiers trained with cross-entropy loss to override the unconditional token-level distributions learned from typical sparse single-disconnection reaction datasets. We overcome this issue with a novel method called Sequence Completion Ranking (SCR), which employs contrastive argumentation and a margin-based loss to calibrate the classifier so that it can meaningfully discriminate between continuations during decoding. We formally establish that margin-calibrated classifiers can expand the set of property-satisfying sequences reachable under guided beam search. Empirically, on USPTO-190, given chemist-specified guidance targets, SCR substantially improves multi-step solve rates from $16.8\%$ (unguided generator) to $78.4\%$ with reaction-type guidance and $95.3\%$ with Tanimoto guidance, unlocking valid routes for 33 targets ($17.4\%$) previously unsolvable with baselines. Our method also effectively closes the long-standing diversity gap between template-free and template-based methods.
Alignment is Key for Applying Diffusion Models to Retrosynthesis
May 27, 2024Retrosynthesis, the task of identifying precursors for a given molecule, can be naturally framed as a conditional graph generation task. Diffusion models are a particularly promising modelling approach, enabling post-hoc conditioning and trading off quality for speed during generation. We show mathematically that permutation equivariant denoisers severely limit the expressiveness of graph diffusion models and thus their adaptation to retrosynthesis. To address this limitation, we relax the equivariance requirement such that it only applies to aligned permutations of the conditioning and the generated graphs obtained through atom mapping. Our new denoiser achieves the highest top-$1$ accuracy ($54.7$\%) across template-free and template-based methods on USPTO-50k. We also demonstrate the ability for flexible post-training conditioning and good sample quality with small diffusion step counts, highlighting the potential for interactive applications and additional controls for multi-step planning.
The Transitive Information Theory and its Application to Deep Generative Models
Mar 28, 2022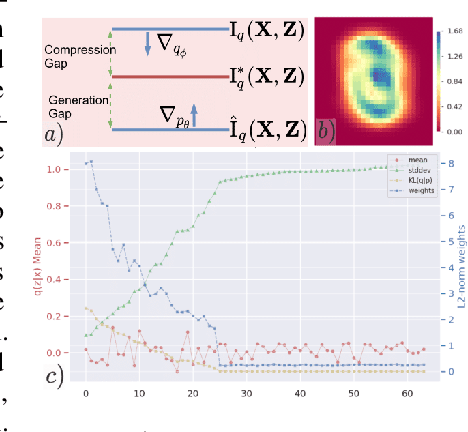

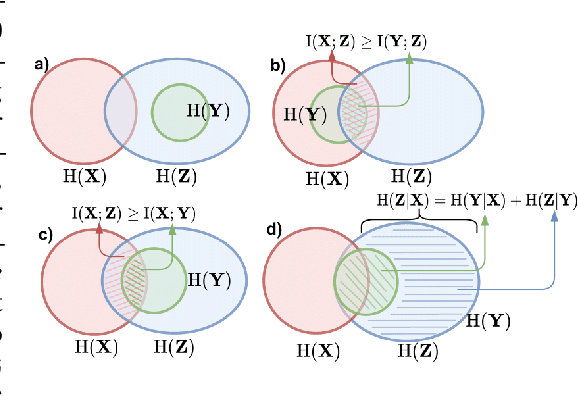
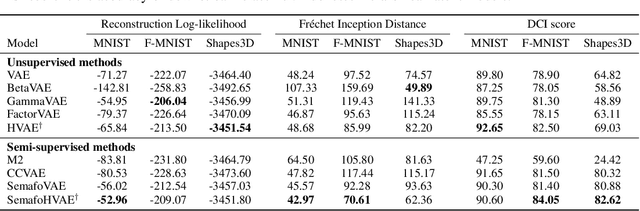
Paradoxically, a Variational Autoencoder (VAE) could be pushed in two opposite directions, utilizing powerful decoder model for generating realistic images but collapsing the learned representation, or increasing regularization coefficient for disentangling representation but ultimately generating blurry examples. Existing methods narrow the issues to the rate-distortion trade-off between compression and reconstruction. We argue that a good reconstruction model does learn high capacity latents that encode more details, however, its use is hindered by two major issues: the prior is random noise which is completely detached from the posterior and allow no controllability in the generation; mean-field variational inference doesn't enforce hierarchy structure which makes the task of recombining those units into plausible novel output infeasible. As a result, we develop a system that learns a hierarchy of disentangled representation together with a mechanism for recombining the learned representation for generalization. This is achieved by introducing a minimal amount of inductive bias to learn controllable prior for the VAE. The idea is supported by here developed transitive information theory, that is, the mutual information between two target variables could alternately be maximized through the mutual information to the third variable, thus bypassing the rate-distortion bottleneck in VAE design. In particular, we show that our model, named SemafoVAE (inspired by the similar concept in computer science), could generate high-quality examples in a controllable manner, perform smooth traversals of the disentangled factors and intervention at a different level of representation hierarchy.