 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNested Variational Autoencoder for Topic Modeling on Microtexts with Word Vectors
Jun 03, 2019
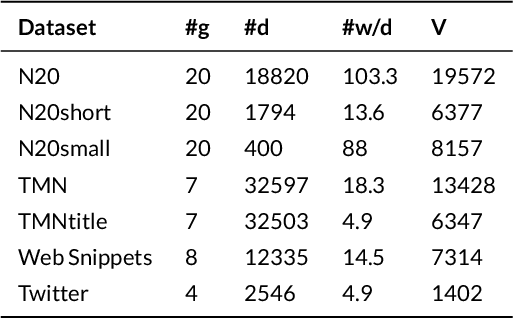
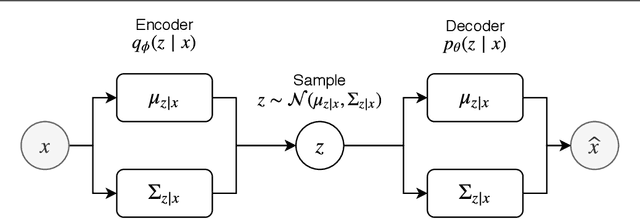
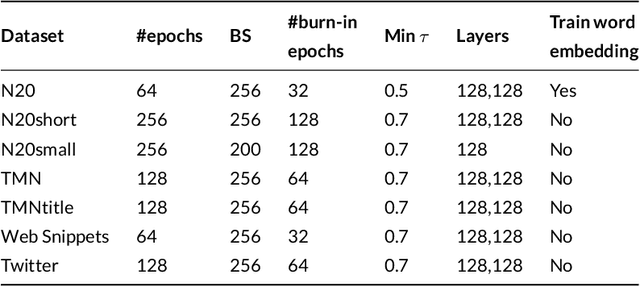
Most of the information on the Internet is represented in the form of microtexts, which are short text snippets like news headlines or tweets. These source of information is abundant and mining this data could uncover meaningful insights. Topic modeling is one of the popular methods to extract knowledge from a collection of documents, nevertheless conventional topic models such as Latent Dirichlet Allocation (LDA) is unable to perform well on short documents, mostly due to the scarcity of word co-occurrence statistics embedded in the data. The objective of our research is to create a topic model which can achieve great performances on microtexts while requiring a small runtime for scalability to large datasets. To solve the lack of information of microtexts, we allow our method to take advantage of word embeddings for additional knowledge of relationships between words. For speed and scalability, we apply Auto-Encoding Variational Bayes, an algorithm that can perform efficient black-box inference in probabilistic models. The result of our work is a novel topic model called Nested Variational Autoencoder which is a distribution that takes into account word vectors and is parameterized by a neural network architecture. For optimization, the model is trained to approximate the posterior distribution of the original LDA model. Experiments show the improvements of our model on microtexts as well as its runtime advantage.
Combination of Domain Knowledge and Deep Learning for Sentiment Analysis of Short and Informal Messages on Social Media
Feb 16, 2019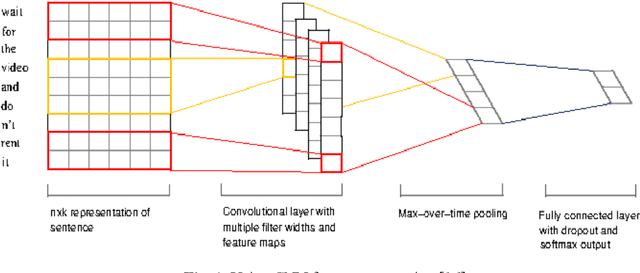
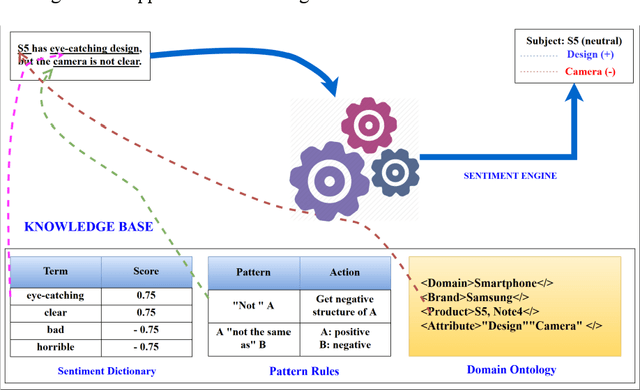
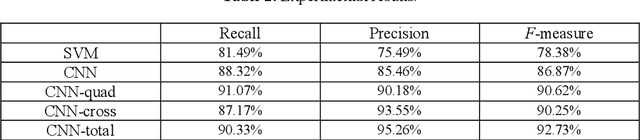
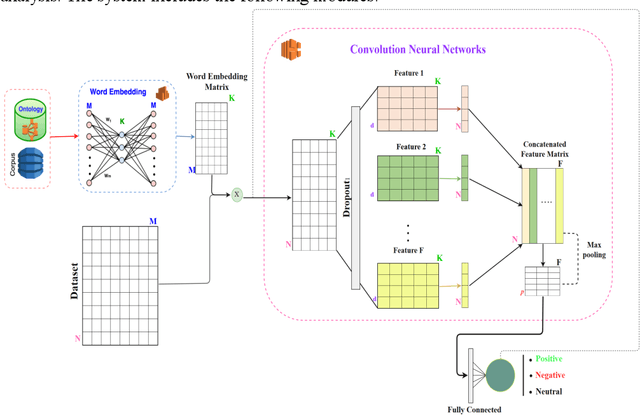
Sentiment analysis has been emerging recently as one of the major natural language processing (NLP) tasks in many applications. Especially, as social media channels (e.g. social networks or forums) have become significant sources for brands to observe user opinions about their products, this task is thus increasingly crucial. However, when applied with real data obtained from social media, we notice that there is a high volume of short and informal messages posted by users on those channels. This kind of data makes the existing works suffer from many difficulties to handle, especially ones using deep learning approaches. In this paper, we propose an approach to handle this problem. This work is extended from our previous work, in which we proposed to combine the typical deep learning technique of Convolutional Neural Networks with domain knowledge. The combination is used for acquiring additional training data augmentation and a more reasonable loss function. In this work, we further improve our architecture by various substantial enhancements, including negation-based data augmentation, transfer learning for word embeddings, the combination of word-level embeddings and character-level embeddings, and using multitask learning technique for attaching domain knowledge rules in the learning process. Those enhancements, specifically aiming to handle short and informal messages, help us to enjoy significant improvement in performance once experimenting on real datasets.
Combination of Domain Knowledge and Deep Learning for Sentiment Analysis
Jun 26, 2018The emerging technique of deep learning has been widely applied in many different areas. However, when adopted in a certain specific domain, this technique should be combined with domain knowledge to improve efficiency and accuracy. In particular, when analyzing the applications of deep learning in sentiment analysis, we found that the current approaches are suffering from the following drawbacks: (i) the existing works have not paid much attention to the importance of different types of sentiment terms, which is an important concept in this area; and (ii) the loss function currently employed does not well reflect the degree of error of sentiment misclassification. To overcome such problem, we propose to combine domain knowledge with deep learning. Our proposal includes using sentiment scores, learnt by regression, to augment training data; and introducing penalty matrix for enhancing the loss function of cross entropy. When experimented, we achieved a significant improvement in classification results.