 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNested Variational Autoencoder for Topic Modeling on Microtexts with Word Vectors
Paper and Code

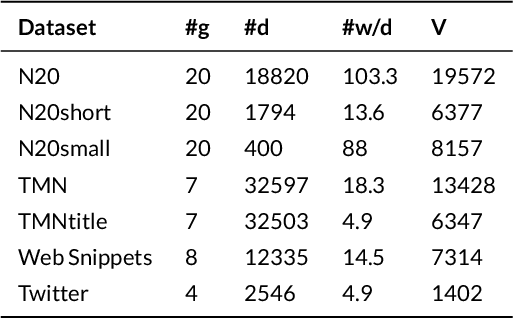
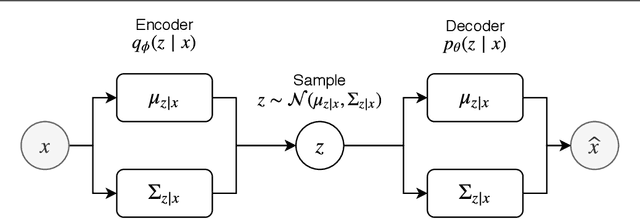
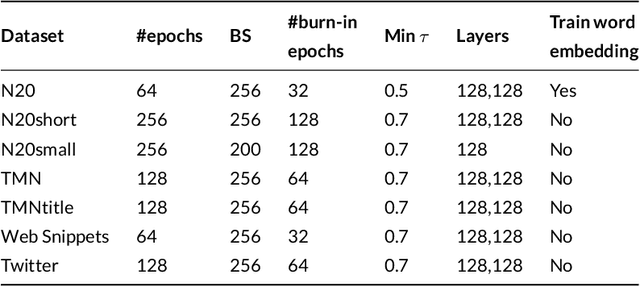
Most of the information on the Internet is represented in the form of microtexts, which are short text snippets like news headlines or tweets. These source of information is abundant and mining this data could uncover meaningful insights. Topic modeling is one of the popular methods to extract knowledge from a collection of documents, nevertheless conventional topic models such as Latent Dirichlet Allocation (LDA) is unable to perform well on short documents, mostly due to the scarcity of word co-occurrence statistics embedded in the data. The objective of our research is to create a topic model which can achieve great performances on microtexts while requiring a small runtime for scalability to large datasets. To solve the lack of information of microtexts, we allow our method to take advantage of word embeddings for additional knowledge of relationships between words. For speed and scalability, we apply Auto-Encoding Variational Bayes, an algorithm that can perform efficient black-box inference in probabilistic models. The result of our work is a novel topic model called Nested Variational Autoencoder which is a distribution that takes into account word vectors and is parameterized by a neural network architecture. For optimization, the model is trained to approximate the posterior distribution of the original LDA model. Experiments show the improvements of our model on microtexts as well as its runtime advantage.