 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaking in Words, Thinking in Logic: A Dual-Process Framework in QA Systems
Jul 28, 2025Recent advances in large language models (LLMs) have significantly enhanced question-answering (QA) capabilities, particularly in open-domain contexts. However, in closed-domain scenarios such as education, healthcare, and law, users demand not only accurate answers but also transparent reasoning and explainable decision-making processes. While neural-symbolic (NeSy) frameworks have emerged as a promising solution, leveraging LLMs for natural language understanding and symbolic systems for formal reasoning, existing approaches often rely on large-scale models and exhibit inefficiencies in translating natural language into formal logic representations. To address these limitations, we introduce Text-JEPA (Text-based Joint-Embedding Predictive Architecture), a lightweight yet effective framework for converting natural language into first-order logic (NL2FOL). Drawing inspiration from dual-system cognitive theory, Text-JEPA emulates System 1 by efficiently generating logic representations, while the Z3 solver operates as System 2, enabling robust logical inference. To rigorously evaluate the NL2FOL-to-reasoning pipeline, we propose a comprehensive evaluation framework comprising three custom metrics: conversion score, reasoning score, and Spearman rho score, which collectively capture the quality of logical translation and its downstream impact on reasoning accuracy. Empirical results on domain-specific datasets demonstrate that Text-JEPA achieves competitive performance with significantly lower computational overhead compared to larger LLM-based systems. Our findings highlight the potential of structured, interpretable reasoning frameworks for building efficient and explainable QA systems in specialized domains.
Leveraging Anthropometric Measurements to Improve Human Mesh Estimation and Ensure Consistent Body Shapes
Sep 27, 2024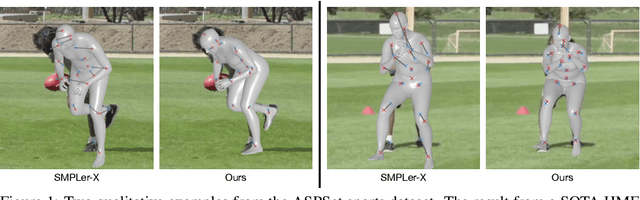
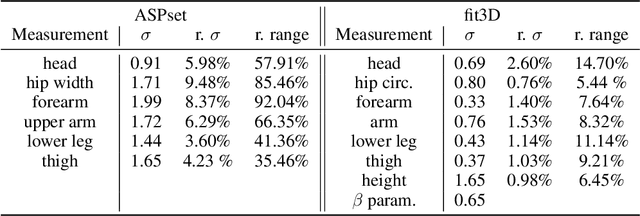
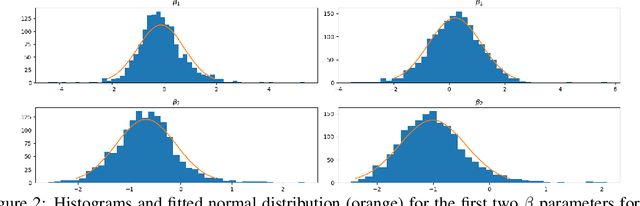
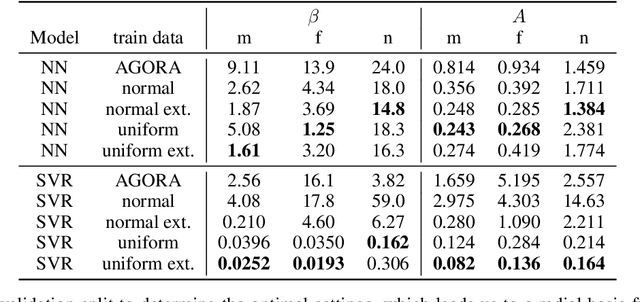
The basic body shape of a person does not change within a single video. However, most SOTA human mesh estimation (HME) models output a slightly different body shape for each video frame, which results in inconsistent body shapes for the same person. In contrast, we leverage anthropometric measurements like tailors are already obtaining from humans for centuries. We create a model called A2B that converts such anthropometric measurements to body shape parameters of human mesh models. Moreover, we find that finetuned SOTA 3D human pose estimation (HPE) models outperform HME models regarding the precision of the estimated keypoints. We show that applying inverse kinematics (IK) to the results of such a 3D HPE model and combining the resulting body pose with the A2B body shape leads to superior and consistent human meshes for challenging datasets like ASPset or fit3D, where we can lower the MPJPE by over 30 mm compared to SOTA HME models. Further, replacing HME models estimates of the body shape parameters with A2B model results not only increases the performance of these HME models, but also leads to consistent body shapes.
Cross-Data Knowledge Graph Construction for LLM-enabled Educational Question-Answering System: A~Case~Study~at~HCMUT
Apr 14, 2024



In today's rapidly evolving landscape of Artificial Intelligence, large language models (LLMs) have emerged as a vibrant research topic. LLMs find applications in various fields and contribute significantly. Despite their powerful language capabilities, similar to pre-trained language models (PLMs), LLMs still face challenges in remembering events, incorporating new information, and addressing domain-specific issues or hallucinations. To overcome these limitations, researchers have proposed Retrieval-Augmented Generation (RAG) techniques, some others have proposed the integration of LLMs with Knowledge Graphs (KGs) to provide factual context, thereby improving performance and delivering more accurate feedback to user queries. Education plays a crucial role in human development and progress. With the technology transformation, traditional education is being replaced by digital or blended education. Therefore, educational data in the digital environment is increasing day by day. Data in higher education institutions are diverse, comprising various sources such as unstructured/structured text, relational databases, web/app-based API access, etc. Constructing a Knowledge Graph from these cross-data sources is not a simple task. This article proposes a method for automatically constructing a Knowledge Graph from multiple data sources and discusses some initial applications (experimental trials) of KG in conjunction with LLMs for question-answering tasks.