 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking and Explaining Deep Learning Cortical Lesion MRI Segmentation in Multiple Sclerosis
Jul 16, 2025Cortical lesions (CLs) have emerged as valuable biomarkers in multiple sclerosis (MS), offering high diagnostic specificity and prognostic relevance. However, their routine clinical integration remains limited due to subtle magnetic resonance imaging (MRI) appearance, challenges in expert annotation, and a lack of standardized automated methods. We propose a comprehensive multi-centric benchmark of CL detection and segmentation in MRI. A total of 656 MRI scans, including clinical trial and research data from four institutions, were acquired at 3T and 7T using MP2RAGE and MPRAGE sequences with expert-consensus annotations. We rely on the self-configuring nnU-Net framework, designed for medical imaging segmentation, and propose adaptations tailored to the improved CL detection. We evaluated model generalization through out-of-distribution testing, demonstrating strong lesion detection capabilities with an F1-score of 0.64 and 0.5 in and out of the domain, respectively. We also analyze internal model features and model errors for a better understanding of AI decision-making. Our study examines how data variability, lesion ambiguity, and protocol differences impact model performance, offering future recommendations to address these barriers to clinical adoption. To reinforce the reproducibility, the implementation and models will be publicly accessible and ready to use at https://github.com/Medical-Image-Analysis-Laboratory/ and https://doi.org/10.5281/zenodo.15911797.
Explainability of AI Uncertainty: Application to Multiple Sclerosis Lesion Segmentation on MRI
Apr 07, 2025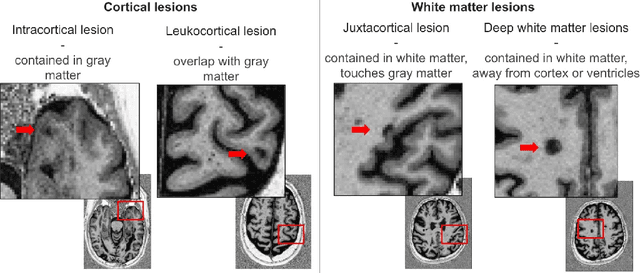



Trustworthy artificial intelligence (AI) is essential in healthcare, particularly for high-stakes tasks like medical image segmentation. Explainable AI and uncertainty quantification significantly enhance AI reliability by addressing key attributes such as robustness, usability, and explainability. Despite extensive technical advances in uncertainty quantification for medical imaging, understanding the clinical informativeness and interpretability of uncertainty remains limited. This study introduces a novel framework to explain the potential sources of predictive uncertainty, specifically in cortical lesion segmentation in multiple sclerosis using deep ensembles. The proposed analysis shifts the focus from the uncertainty-error relationship towards relevant medical and engineering factors. Our findings reveal that instance-wise uncertainty is strongly related to lesion size, shape, and cortical involvement. Expert rater feedback confirms that similar factors impede annotator confidence. Evaluations conducted on two datasets (206 patients, almost 2000 lesions) under both in-domain and distribution-shift conditions highlight the utility of the framework in different scenarios.
On the Role of Visual Grounding in VQA
Jun 26, 2024



Visual Grounding (VG) in VQA refers to a model's proclivity to infer answers based on question-relevant image regions. Conceptually, VG identifies as an axiomatic requirement of the VQA task. In practice, however, DNN-based VQA models are notorious for bypassing VG by way of shortcut (SC) learning without suffering obvious performance losses in standard benchmarks. To uncover the impact of SC learning, Out-of-Distribution (OOD) tests have been proposed that expose a lack of VG with low accuracy. These tests have since been at the center of VG research and served as basis for various investigations into VG's impact on accuracy. However, the role of VG in VQA still remains not fully understood and has not yet been properly formalized. In this work, we seek to clarify VG's role in VQA by formalizing it on a conceptual level. We propose a novel theoretical framework called "Visually Grounded Reasoning" (VGR) that uses the concepts of VG and Reasoning to describe VQA inference in ideal OOD testing. By consolidating fundamental insights into VG's role in VQA, VGR helps to reveal rampant VG-related SC exploitation in OOD testing, which explains why the relationship between VG and OOD accuracy has been difficult to define. Finally, we propose an approach to create OOD tests that properly emphasize a requirement for VG, and show how to improve performance on them.
Uncovering the Full Potential of Visual Grounding Methods in VQA
Jan 15, 2024

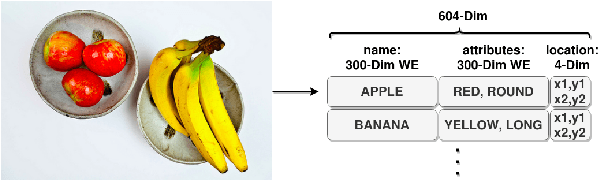
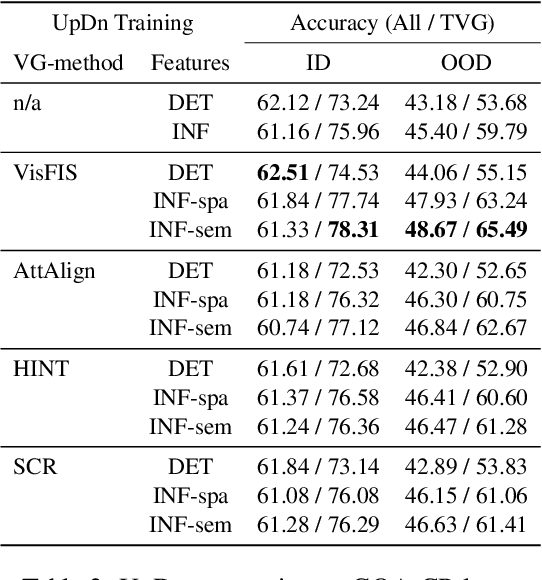
Visual Grounding (VG) methods in Visual Question Answering (VQA) attempt to improve VQA performance by strengthening a model's reliance on question-relevant visual information. The presence of such relevant information in the visual input is typically assumed in training and testing. This assumption, however, is inherently flawed when dealing with imperfect image representations common in large-scale VQA, where the information carried by visual features frequently deviates from expected ground-truth contents. As a result, training and testing of VG-methods is performed with largely inaccurate data, which obstructs proper assessment of their potential benefits. In this work, we demonstrate that current evaluation schemes for VG-methods are problematic due to the flawed assumption of availability of relevant visual information. Our experiments show that the potential benefits of these methods are severely underestimated as a result.
Measuring Faithful and Plausible Visual Grounding in VQA
May 24, 2023



Metrics for Visual Grounding (VG) in Visual Question Answering (VQA) systems primarily aim to measure a system's reliance on relevant parts of the image when inferring an answer to the given question. Lack of VG has been a common problem among state-of-the-art VQA systems and can manifest in over-reliance on irrelevant image parts or a disregard for the visual modality entirely. Although inference capabilities of VQA models are often illustrated by a few qualitative illustrations, most systems are not quantitatively assessed for their VG properties. We believe, an easily calculated criterion for meaningfully measuring a system's VG can help remedy this shortcoming, as well as add another valuable dimension to model evaluations and analysis. To this end, we propose a new VG metric that captures if a model a) identifies question-relevant objects in the scene, and b) actually relies on the information contained in the relevant objects when producing its answer, i.e., if its visual grounding is both "faithful" and "plausible". Our metric, called "Faithful and Plausible Visual Grounding" (FPVG), is straightforward to determine for most VQA model designs. We give a detailed description of FPVG and evaluate several reference systems spanning various VQA architectures. Code to support the metric calculations on the GQA data set is available on GitHub.
Visually Grounded VQA by Lattice-based Retrieval
Nov 15, 2022



Visual Grounding (VG) in Visual Question Answering (VQA) systems describes how well a system manages to tie a question and its answer to relevant image regions. Systems with strong VG are considered intuitively interpretable and suggest an improved scene understanding. While VQA accuracy performances have seen impressive gains over the past few years, explicit improvements to VG performance and evaluation thereof have often taken a back seat on the road to overall accuracy improvements. A cause of this originates in the predominant choice of learning paradigm for VQA systems, which consists of training a discriminative classifier over a predetermined set of answer options. In this work, we break with the dominant VQA modeling paradigm of classification and investigate VQA from the standpoint of an information retrieval task. As such, the developed system directly ties VG into its core search procedure. Our system operates over a weighted, directed, acyclic graph, a.k.a. "lattice", which is derived from the scene graph of a given image in conjunction with region-referring expressions extracted from the question. We give a detailed analysis of our approach and discuss its distinctive properties and limitations. Our approach achieves the strongest VG performance among examined systems and exhibits exceptional generalization capabilities in a number of scenarios.
Adventurer's Treasure Hunt: A Transparent System for Visually Grounded Compositional Visual Question Answering based on Scene Graphs
Jun 28, 2021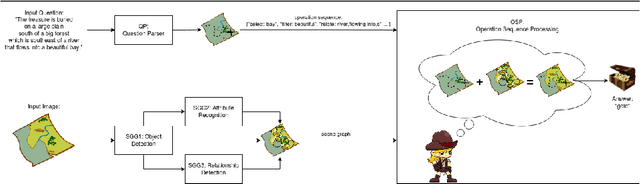
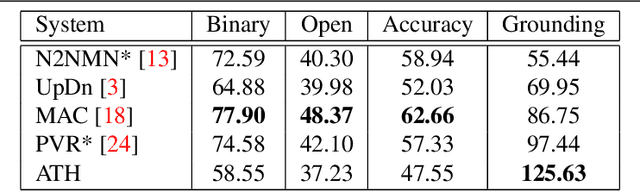
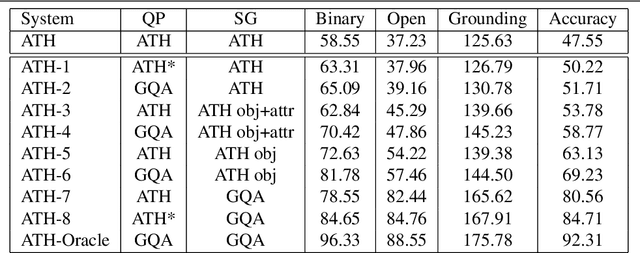
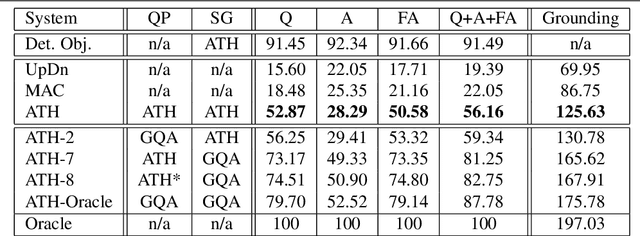
With the expressed goal of improving system transparency and visual grounding in the reasoning process in VQA, we present a modular system for the task of compositional VQA based on scene graphs. Our system is called "Adventurer's Treasure Hunt" (or ATH), named after an analogy we draw between our model's search procedure for an answer and an adventurer's search for treasure. We developed ATH with three characteristic features in mind: 1. By design, ATH allows us to explicitly quantify the impact of each of the sub-components on overall VQA performance, as well as their performance on their individual sub-task. 2. By modeling the search task after a treasure hunt, ATH inherently produces an explicit, visually grounded inference path for the processed question. 3. ATH is the first GQA-trained VQA system that dynamically extracts answers by querying the visual knowledge base directly, instead of selecting one from a specially learned classifier's output distribution over a pre-fixed answer vocabulary. We report detailed results on all components and their contributions to overall VQA performance on the GQA dataset and show that ATH achieves the highest visual grounding score among all examined systems.