 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJURY-RL: Votes Propose, Proofs Dispose for Label-Free RLVR
Apr 28, 2026Reinforcement learning with verifiable rewards (RLVR) enhances the reasoning of large language models (LLMs), but standard RLVR often depends on human-annotated answers or carefully curated reward specifications. In machine-checkable domains, label-free alternatives such as majority voting or LLM-as-a-judge remove annotation cost but can introduce false positives that destabilize training. We introduce JURY-RL, a label-free RLVR framework that decouples answer proposal from reward disposal: votes from model rollouts propose a candidate answer, and a formal verifier determines whether that candidate can receive positive reward. Concretely, only rollouts matching the plurality-voted answer are rewarded when that answer is successfully verified in Lean. When verification is inconclusive, we invoke ResZero (Residual-Zero), a fallback reward that discards the unverified plurality proposal and redistributes a zero-mean, variance-preserving signal over the residual answers. This design maintains a stable optimization gradient without reinforcing unverifiable consensus. Across three backbone models trained on mathematical data, JURY-RL consistently outperforms other label-free baselines on mathematical reasoning benchmarks and transfers competitively to code generation and general benchmarks. It attains pass@1 performance comparable to supervised ground-truth training, with superior generalization demonstrated by higher pass@k and response diversity.
FutureX-Pro: Extending Future Prediction to High-Value Vertical Domains
Jan 18, 2026Building upon FutureX, which established a live benchmark for general-purpose future prediction, this report introduces FutureX-Pro, including FutureX-Finance, FutureX-Retail, FutureX-PublicHealth, FutureX-NaturalDisaster, and FutureX-Search. These together form a specialized framework extending agentic future prediction to high-value vertical domains. While generalist agents demonstrate proficiency in open-domain search, their reliability in capital-intensive and safety-critical sectors remains under-explored. FutureX-Pro targets four economically and socially pivotal verticals: Finance, Retail, Public Health, and Natural Disaster. We benchmark agentic Large Language Models (LLMs) on entry-level yet foundational prediction tasks -- ranging from forecasting market indicators and supply chain demands to tracking epidemic trends and natural disasters. By adapting the contamination-free, live-evaluation pipeline of FutureX, we assess whether current State-of-the-Art (SOTA) agentic LLMs possess the domain grounding necessary for industrial deployment. Our findings reveal the performance gap between generalist reasoning and the precision required for high-value vertical applications.
NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
Dec 14, 2025Recent advances in coding agents suggest rapid progress toward autonomous software development, yet existing benchmarks fail to rigorously evaluate the long-horizon capabilities required to build complete software systems. Most prior evaluations focus on localized code generation, scaffolded completion, or short-term repair tasks, leaving open the question of whether agents can sustain coherent reasoning, planning, and execution over the extended horizons demanded by real-world repository construction. To address this gap, we present NL2Repo Bench, a benchmark explicitly designed to evaluate the long-horizon repository generation ability of coding agents. Given only a single natural-language requirements document and an empty workspace, agents must autonomously design the architecture, manage dependencies, implement multi-module logic, and produce a fully installable Python library. Our experiments across state-of-the-art open- and closed-source models reveal that long-horizon repository generation remains largely unsolved: even the strongest agents achieve below 40% average test pass rates and rarely complete an entire repository correctly. Detailed analysis uncovers fundamental long-horizon failure modes, including premature termination, loss of global coherence, fragile cross-file dependencies, and inadequate planning over hundreds of interaction steps. NL2Repo Bench establishes a rigorous, verifiable testbed for measuring sustained agentic competence and highlights long-horizon reasoning as a central bottleneck for the next generation of autonomous coding agents.
LPFQA: A Long-Tail Professional Forum-based Benchmark for LLM Evaluation
Nov 09, 2025Large Language Models (LLMs) have made rapid progress in reasoning, question answering, and professional applications; however, their true capabilities remain difficult to evaluate using existing benchmarks. Current datasets often focus on simplified tasks or artificial scenarios, overlooking long-tail knowledge and the complexities of real-world applications. To bridge this gap, we propose LPFQA, a long-tail knowledge-based benchmark derived from authentic professional forums across 20 academic and industrial fields, covering 502 tasks grounded in practical expertise. LPFQA introduces four key innovations: fine-grained evaluation dimensions that target knowledge depth, reasoning, terminology comprehension, and contextual analysis; a hierarchical difficulty structure that ensures semantic clarity and unique answers; authentic professional scenario modeling with realistic user personas; and interdisciplinary knowledge integration across diverse domains. We evaluated 12 mainstream LLMs on LPFQA and observed significant performance disparities, especially in specialized reasoning tasks. LPFQA provides a robust, authentic, and discriminative benchmark for advancing LLM evaluation and guiding future model development.
Benchmarking and Explaining Deep Learning Cortical Lesion MRI Segmentation in Multiple Sclerosis
Jul 16, 2025Cortical lesions (CLs) have emerged as valuable biomarkers in multiple sclerosis (MS), offering high diagnostic specificity and prognostic relevance. However, their routine clinical integration remains limited due to subtle magnetic resonance imaging (MRI) appearance, challenges in expert annotation, and a lack of standardized automated methods. We propose a comprehensive multi-centric benchmark of CL detection and segmentation in MRI. A total of 656 MRI scans, including clinical trial and research data from four institutions, were acquired at 3T and 7T using MP2RAGE and MPRAGE sequences with expert-consensus annotations. We rely on the self-configuring nnU-Net framework, designed for medical imaging segmentation, and propose adaptations tailored to the improved CL detection. We evaluated model generalization through out-of-distribution testing, demonstrating strong lesion detection capabilities with an F1-score of 0.64 and 0.5 in and out of the domain, respectively. We also analyze internal model features and model errors for a better understanding of AI decision-making. Our study examines how data variability, lesion ambiguity, and protocol differences impact model performance, offering future recommendations to address these barriers to clinical adoption. To reinforce the reproducibility, the implementation and models will be publicly accessible and ready to use at https://github.com/Medical-Image-Analysis-Laboratory/ and https://doi.org/10.5281/zenodo.15911797.
From Data-Centric to Sample-Centric: Enhancing LLM Reasoning via Progressive Optimization
Jul 09, 2025



Reinforcement learning with verifiable rewards (RLVR) has recently advanced the reasoning capabilities of large language models (LLMs). While prior work has emphasized algorithmic design, data curation, and reward shaping, we investigate RLVR from a sample-centric perspective and introduce LPPO (Learning-Progress and Prefix-guided Optimization), a framework of progressive optimization techniques. Our work addresses a critical question: how to best leverage a small set of trusted, high-quality demonstrations, rather than simply scaling up data volume. First, motivated by how hints aid human problem-solving, we propose prefix-guided sampling, an online data augmentation method that incorporates partial solution prefixes from expert demonstrations to guide the policy, particularly for challenging instances. Second, inspired by how humans focus on important questions aligned with their current capabilities, we introduce learning-progress weighting, a dynamic strategy that adjusts each training sample's influence based on model progression. We estimate sample-level learning progress via an exponential moving average of per-sample pass rates, promoting samples that foster learning and de-emphasizing stagnant ones. Experiments on mathematical-reasoning benchmarks demonstrate that our methods outperform strong baselines, yielding faster convergence and a higher performance ceiling.
Explainability of AI Uncertainty: Application to Multiple Sclerosis Lesion Segmentation on MRI
Apr 07, 2025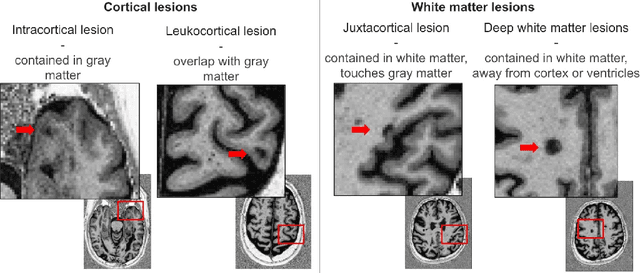



Trustworthy artificial intelligence (AI) is essential in healthcare, particularly for high-stakes tasks like medical image segmentation. Explainable AI and uncertainty quantification significantly enhance AI reliability by addressing key attributes such as robustness, usability, and explainability. Despite extensive technical advances in uncertainty quantification for medical imaging, understanding the clinical informativeness and interpretability of uncertainty remains limited. This study introduces a novel framework to explain the potential sources of predictive uncertainty, specifically in cortical lesion segmentation in multiple sclerosis using deep ensembles. The proposed analysis shifts the focus from the uncertainty-error relationship towards relevant medical and engineering factors. Our findings reveal that instance-wise uncertainty is strongly related to lesion size, shape, and cortical involvement. Expert rater feedback confirms that similar factors impede annotator confidence. Evaluations conducted on two datasets (206 patients, almost 2000 lesions) under both in-domain and distribution-shift conditions highlight the utility of the framework in different scenarios.
Interpretability of Uncertainty: Exploring Cortical Lesion Segmentation in Multiple Sclerosis
Jul 08, 2024


Uncertainty quantification (UQ) has become critical for evaluating the reliability of artificial intelligence systems, especially in medical image segmentation. This study addresses the interpretability of instance-wise uncertainty values in deep learning models for focal lesion segmentation in magnetic resonance imaging, specifically cortical lesion (CL) segmentation in multiple sclerosis. CL segmentation presents several challenges, including the complexity of manual segmentation, high variability in annotation, data scarcity, and class imbalance, all of which contribute to aleatoric and epistemic uncertainty. We explore how UQ can be used not only to assess prediction reliability but also to provide insights into model behavior, detect biases, and verify the accuracy of UQ methods. Our research demonstrates the potential of instance-wise uncertainty values to offer post hoc global model explanations, serving as a sanity check for the model. The implementation is available at https://github.com/NataliiaMolch/interpret-lesion-unc.
GAMER-MRIL identifies Disability-Related Brain Changes in Multiple Sclerosis
Aug 15, 2023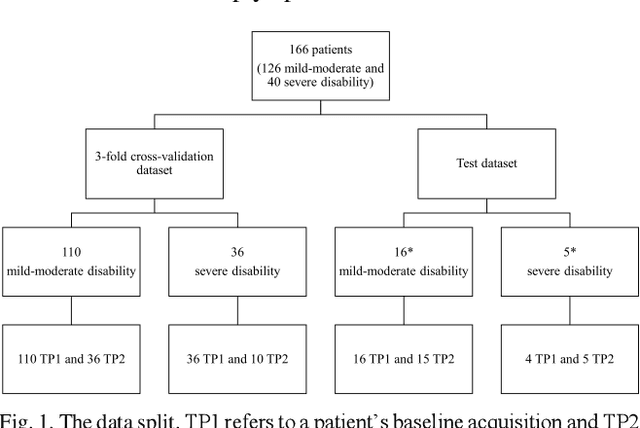
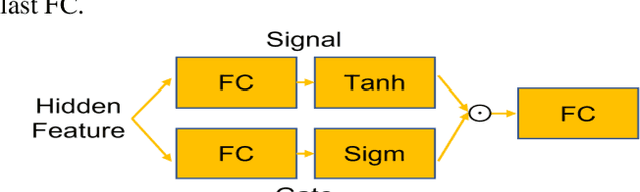
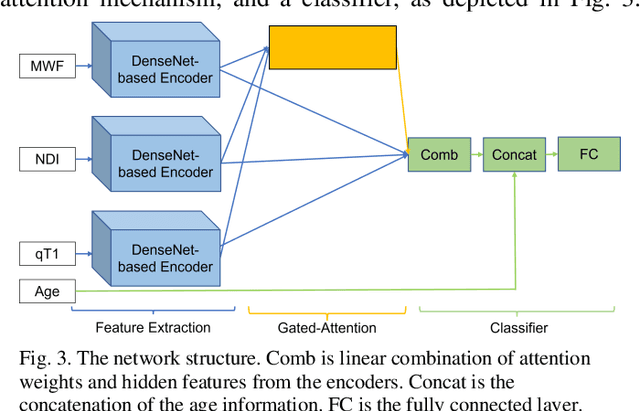
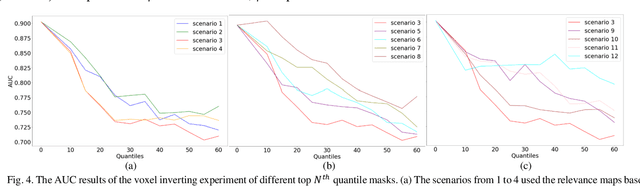
Objective: Identifying disability-related brain changes is important for multiple sclerosis (MS) patients. Currently, there is no clear understanding about which pathological features drive disability in single MS patients. In this work, we propose a novel comprehensive approach, GAMER-MRIL, leveraging whole-brain quantitative MRI (qMRI), convolutional neural network (CNN), and an interpretability method from classifying MS patients with severe disability to investigating relevant pathological brain changes. Methods: One-hundred-sixty-six MS patients underwent 3T MRI acquisitions. qMRI informative of microstructural brain properties was reconstructed, including quantitative T1 (qT1), myelin water fraction (MWF), and neurite density index (NDI). To fully utilize the qMRI, GAMER-MRIL extended a gated-attention-based CNN (GAMER-MRI), which was developed to select patch-based qMRI important for a given task/question, to the whole-brain image. To find out disability-related brain regions, GAMER-MRIL modified a structure-aware interpretability method, Layer-wise Relevance Propagation (LRP), to incorporate qMRI. Results: The test performance was AUC=0.885. qT1 was the most sensitive measure related to disability, followed by NDI. The proposed LRP approach obtained more specifically relevant regions than other interpretability methods, including the saliency map, the integrated gradients, and the original LRP. The relevant regions included the corticospinal tract, where average qT1 and NDI significantly correlated with patients' disability scores ($\rho$=-0.37 and 0.44). Conclusion: These results demonstrated that GAMER-MRIL can classify patients with severe disability using qMRI and subsequently identify brain regions potentially important to the integrity of the mobile function. Significance: GAMER-MRIL holds promise for developing biomarkers and increasing clinicians' trust in NN.