 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInpainting Pathology in Lumbar Spine MRI with Latent Diffusion
Jun 04, 2024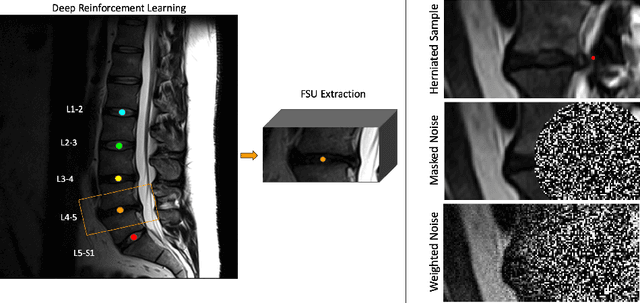
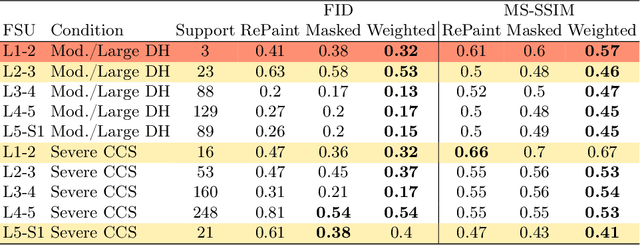
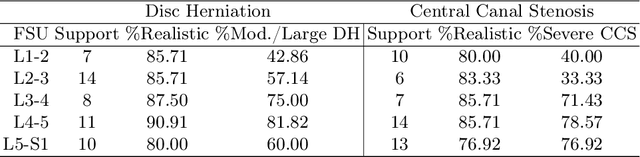
Data driven models for automated diagnosis in radiology suffer from insufficient and imbalanced datasets due to low representation of pathology in a population and the cost of expert annotations. Datasets can be bolstered through data augmentation. However, even when utilizing a full suite of transformations during model training, typical data augmentations do not address variations in human anatomy. An alternative direction is to synthesize data using generative models, which can potentially craft datasets with specific attributes. While this holds promise, commonly used generative models such as Generative Adversarial Networks may inadvertently produce anatomically inaccurate features. On the other hand, diffusion models, which offer greater stability, tend to memorize training data, raising concerns about privacy and generative diversity. Alternatively, inpainting has the potential to augment data through directly inserting pathology in medical images. However, this approach introduces a new challenge: accurately merging the generated pathological features with the surrounding anatomical context. While inpainting is a well established method for addressing simple lesions, its application to pathologies that involve complex structural changes remains relatively unexplored. We propose an efficient method for inpainting pathological features onto healthy anatomy in MRI through voxelwise noise scheduling in a latent diffusion model. We evaluate the method's ability to insert disc herniation and central canal stenosis in lumbar spine sagittal T2 MRI, and it achieves superior Frechet Inception Distance compared to state-of-the-art methods.
GAMER-MRIL identifies Disability-Related Brain Changes in Multiple Sclerosis
Aug 15, 2023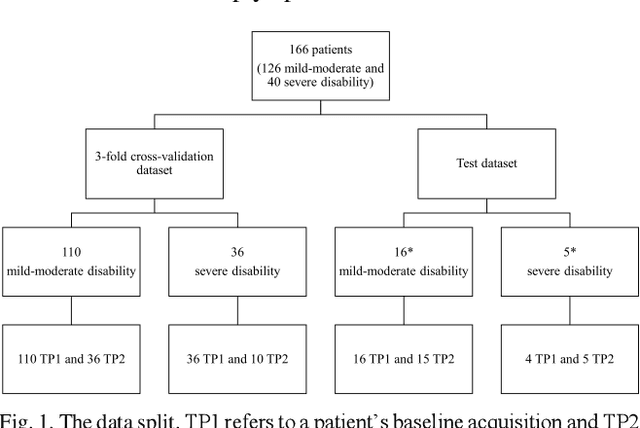
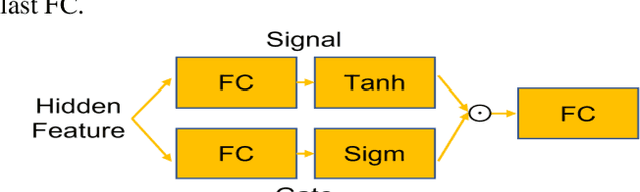
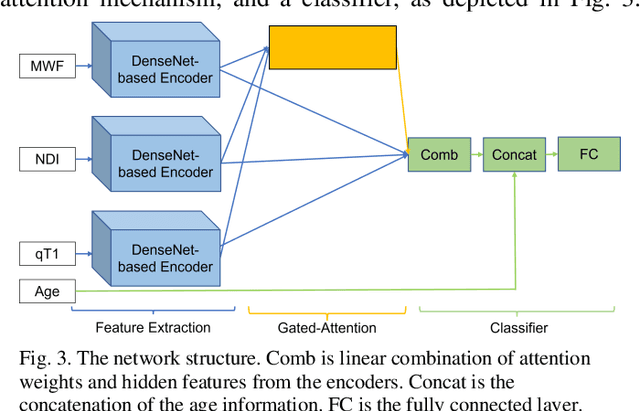
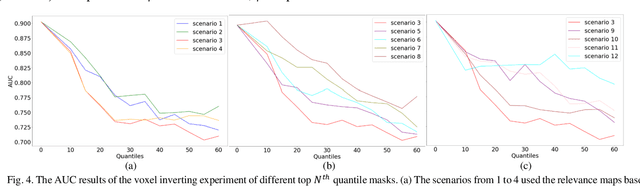
Objective: Identifying disability-related brain changes is important for multiple sclerosis (MS) patients. Currently, there is no clear understanding about which pathological features drive disability in single MS patients. In this work, we propose a novel comprehensive approach, GAMER-MRIL, leveraging whole-brain quantitative MRI (qMRI), convolutional neural network (CNN), and an interpretability method from classifying MS patients with severe disability to investigating relevant pathological brain changes. Methods: One-hundred-sixty-six MS patients underwent 3T MRI acquisitions. qMRI informative of microstructural brain properties was reconstructed, including quantitative T1 (qT1), myelin water fraction (MWF), and neurite density index (NDI). To fully utilize the qMRI, GAMER-MRIL extended a gated-attention-based CNN (GAMER-MRI), which was developed to select patch-based qMRI important for a given task/question, to the whole-brain image. To find out disability-related brain regions, GAMER-MRIL modified a structure-aware interpretability method, Layer-wise Relevance Propagation (LRP), to incorporate qMRI. Results: The test performance was AUC=0.885. qT1 was the most sensitive measure related to disability, followed by NDI. The proposed LRP approach obtained more specifically relevant regions than other interpretability methods, including the saliency map, the integrated gradients, and the original LRP. The relevant regions included the corticospinal tract, where average qT1 and NDI significantly correlated with patients' disability scores ($\rho$=-0.37 and 0.44). Conclusion: These results demonstrated that GAMER-MRIL can classify patients with severe disability using qMRI and subsequently identify brain regions potentially important to the integrity of the mobile function. Significance: GAMER-MRIL holds promise for developing biomarkers and increasing clinicians' trust in NN.
Explaining the Effectiveness of Multi-Task Learning for Efficient Knowledge Extraction from Spine MRI Reports
May 06, 2022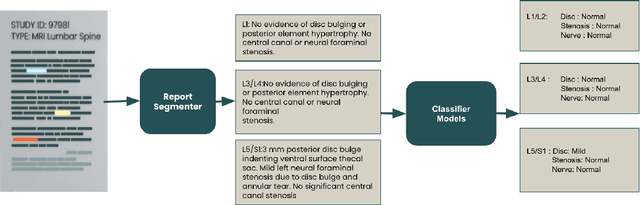
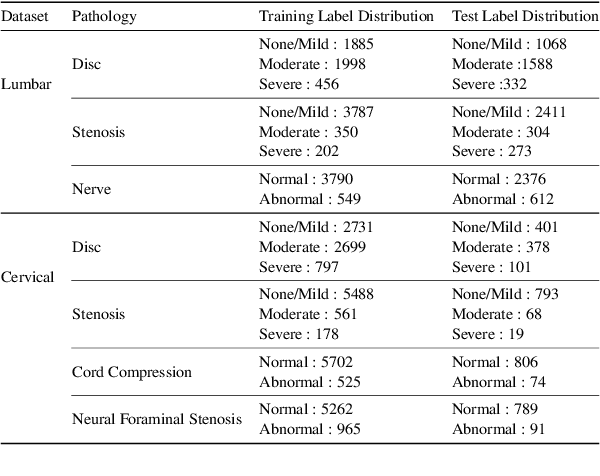
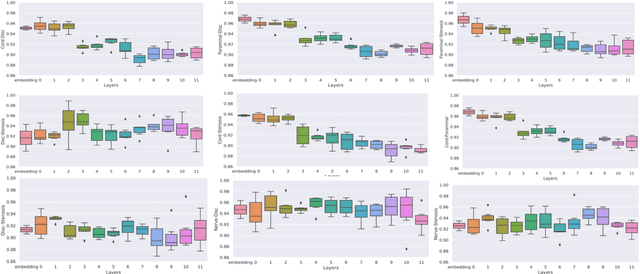
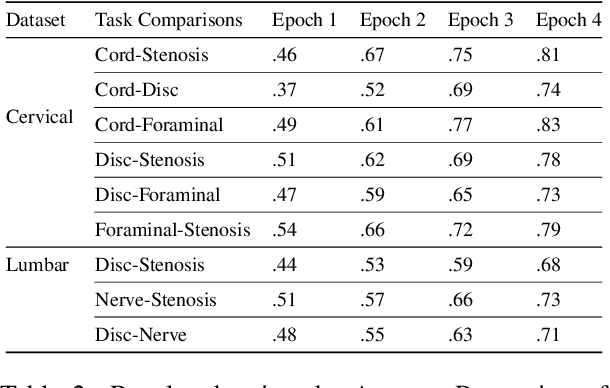
Pretrained Transformer based models finetuned on domain specific corpora have changed the landscape of NLP. However, training or fine-tuning these models for individual tasks can be time consuming and resource intensive. Thus, a lot of current research is focused on using transformers for multi-task learning (Raffel et al.,2020) and how to group the tasks to help a multi-task model to learn effective representations that can be shared across tasks (Standley et al., 2020; Fifty et al., 2021). In this work, we show that a single multi-tasking model can match the performance of task specific models when the task specific models show similar representations across all of their hidden layers and their gradients are aligned, i.e. their gradients follow the same direction. We hypothesize that the above observations explain the effectiveness of multi-task learning. We validate our observations on our internal radiologist-annotated datasets on the cervical and lumbar spine. Our method is simple and intuitive, and can be used in a wide range of NLP problems.
Efficient Extraction of Pathologies from C-Spine Radiology Reports using Multi-Task Learning
Apr 09, 2022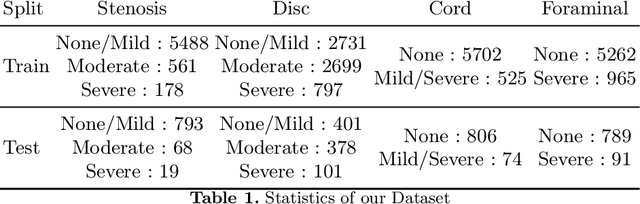
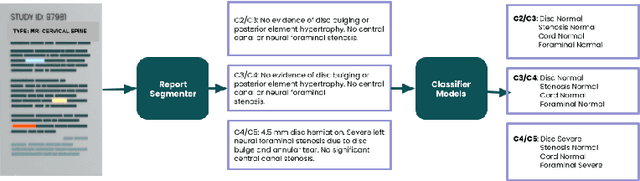
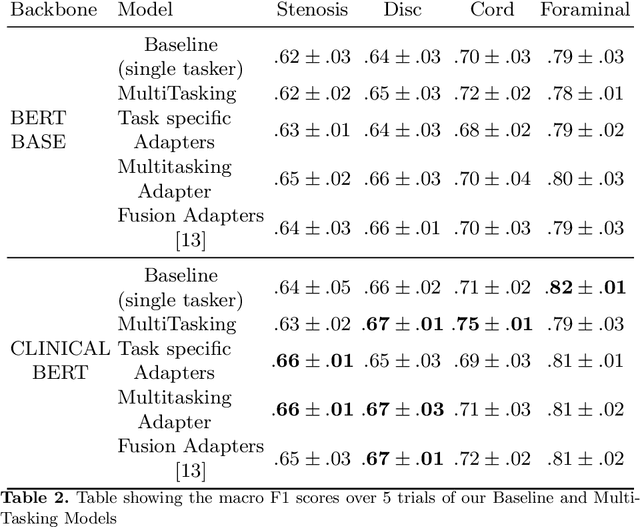

Pretrained Transformer based models finetuned on domain specific corpora have changed the landscape of NLP. Generally, if one has multiple tasks on a given dataset, one may finetune different models or use task specific adapters. In this work, we show that a multi-task model can beat or achieve the performance of multiple BERT-based models finetuned on various tasks and various task specific adapter augmented BERT-based models. We validate our method on our internal radiologist's report dataset on cervical spine. We hypothesize that the tasks are semantically close and related and thus multitask learners are powerful classifiers. Our work opens the scope of using our method to radiologist's reports on various body parts.