 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking and Explaining Deep Learning Cortical Lesion MRI Segmentation in Multiple Sclerosis
Jul 16, 2025Cortical lesions (CLs) have emerged as valuable biomarkers in multiple sclerosis (MS), offering high diagnostic specificity and prognostic relevance. However, their routine clinical integration remains limited due to subtle magnetic resonance imaging (MRI) appearance, challenges in expert annotation, and a lack of standardized automated methods. We propose a comprehensive multi-centric benchmark of CL detection and segmentation in MRI. A total of 656 MRI scans, including clinical trial and research data from four institutions, were acquired at 3T and 7T using MP2RAGE and MPRAGE sequences with expert-consensus annotations. We rely on the self-configuring nnU-Net framework, designed for medical imaging segmentation, and propose adaptations tailored to the improved CL detection. We evaluated model generalization through out-of-distribution testing, demonstrating strong lesion detection capabilities with an F1-score of 0.64 and 0.5 in and out of the domain, respectively. We also analyze internal model features and model errors for a better understanding of AI decision-making. Our study examines how data variability, lesion ambiguity, and protocol differences impact model performance, offering future recommendations to address these barriers to clinical adoption. To reinforce the reproducibility, the implementation and models will be publicly accessible and ready to use at https://github.com/Medical-Image-Analysis-Laboratory/ and https://doi.org/10.5281/zenodo.15911797.
Explainability of AI Uncertainty: Application to Multiple Sclerosis Lesion Segmentation on MRI
Apr 07, 2025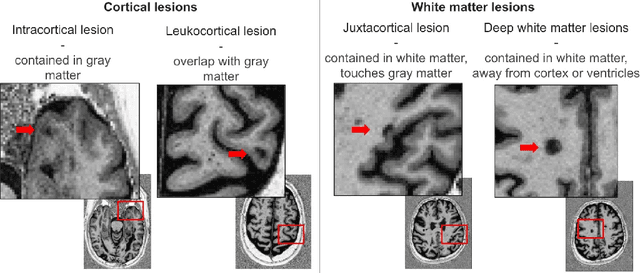



Trustworthy artificial intelligence (AI) is essential in healthcare, particularly for high-stakes tasks like medical image segmentation. Explainable AI and uncertainty quantification significantly enhance AI reliability by addressing key attributes such as robustness, usability, and explainability. Despite extensive technical advances in uncertainty quantification for medical imaging, understanding the clinical informativeness and interpretability of uncertainty remains limited. This study introduces a novel framework to explain the potential sources of predictive uncertainty, specifically in cortical lesion segmentation in multiple sclerosis using deep ensembles. The proposed analysis shifts the focus from the uncertainty-error relationship towards relevant medical and engineering factors. Our findings reveal that instance-wise uncertainty is strongly related to lesion size, shape, and cortical involvement. Expert rater feedback confirms that similar factors impede annotator confidence. Evaluations conducted on two datasets (206 patients, almost 2000 lesions) under both in-domain and distribution-shift conditions highlight the utility of the framework in different scenarios.
Interpretability of Uncertainty: Exploring Cortical Lesion Segmentation in Multiple Sclerosis
Jul 08, 2024


Uncertainty quantification (UQ) has become critical for evaluating the reliability of artificial intelligence systems, especially in medical image segmentation. This study addresses the interpretability of instance-wise uncertainty values in deep learning models for focal lesion segmentation in magnetic resonance imaging, specifically cortical lesion (CL) segmentation in multiple sclerosis. CL segmentation presents several challenges, including the complexity of manual segmentation, high variability in annotation, data scarcity, and class imbalance, all of which contribute to aleatoric and epistemic uncertainty. We explore how UQ can be used not only to assess prediction reliability but also to provide insights into model behavior, detect biases, and verify the accuracy of UQ methods. Our research demonstrates the potential of instance-wise uncertainty values to offer post hoc global model explanations, serving as a sanity check for the model. The implementation is available at https://github.com/NataliiaMolch/interpret-lesion-unc.