 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Diffusion Autoencoders: Enabling Attribute Manipulation in Human Motion Demonstrated on Karate Techniques
Jan 30, 2025Attribute manipulation deals with the problem of changing individual attributes of a data point or a time series, while leaving all other aspects unaffected. This work focuses on the domain of human motion, more precisely karate movement patterns. To the best of our knowledge, it presents the first success at manipulating attributes of human motion data. One of the key requirements for achieving attribute manipulation on human motion is a suitable pose representation. Therefore, we design a novel rotation-based pose representation that enables the disentanglement of the human skeleton and the motion trajectory, while still allowing an accurate reconstruction of the original anatomy. The core idea of the manipulation approach is to use a transformer encoder for discovering high-level semantics, and a diffusion probabilistic model for modeling the remaining stochastic variations. We show that the embedding space obtained from the transformer encoder is semantically meaningful and linear. This enables the manipulation of high-level attributes, by discovering their linear direction of change in the semantic embedding space and moving the embedding along said direction. The code and data are available at https://github.com/anthony-mendil/MoDiffAE.
Measuring Faithful and Plausible Visual Grounding in VQA
May 24, 2023



Metrics for Visual Grounding (VG) in Visual Question Answering (VQA) systems primarily aim to measure a system's reliance on relevant parts of the image when inferring an answer to the given question. Lack of VG has been a common problem among state-of-the-art VQA systems and can manifest in over-reliance on irrelevant image parts or a disregard for the visual modality entirely. Although inference capabilities of VQA models are often illustrated by a few qualitative illustrations, most systems are not quantitatively assessed for their VG properties. We believe, an easily calculated criterion for meaningfully measuring a system's VG can help remedy this shortcoming, as well as add another valuable dimension to model evaluations and analysis. To this end, we propose a new VG metric that captures if a model a) identifies question-relevant objects in the scene, and b) actually relies on the information contained in the relevant objects when producing its answer, i.e., if its visual grounding is both "faithful" and "plausible". Our metric, called "Faithful and Plausible Visual Grounding" (FPVG), is straightforward to determine for most VQA model designs. We give a detailed description of FPVG and evaluate several reference systems spanning various VQA architectures. Code to support the metric calculations on the GQA data set is available on GitHub.
Visually Grounded VQA by Lattice-based Retrieval
Nov 15, 2022



Visual Grounding (VG) in Visual Question Answering (VQA) systems describes how well a system manages to tie a question and its answer to relevant image regions. Systems with strong VG are considered intuitively interpretable and suggest an improved scene understanding. While VQA accuracy performances have seen impressive gains over the past few years, explicit improvements to VG performance and evaluation thereof have often taken a back seat on the road to overall accuracy improvements. A cause of this originates in the predominant choice of learning paradigm for VQA systems, which consists of training a discriminative classifier over a predetermined set of answer options. In this work, we break with the dominant VQA modeling paradigm of classification and investigate VQA from the standpoint of an information retrieval task. As such, the developed system directly ties VG into its core search procedure. Our system operates over a weighted, directed, acyclic graph, a.k.a. "lattice", which is derived from the scene graph of a given image in conjunction with region-referring expressions extracted from the question. We give a detailed analysis of our approach and discuss its distinctive properties and limitations. Our approach achieves the strongest VG performance among examined systems and exhibits exceptional generalization capabilities in a number of scenarios.
Adventurer's Treasure Hunt: A Transparent System for Visually Grounded Compositional Visual Question Answering based on Scene Graphs
Jun 28, 2021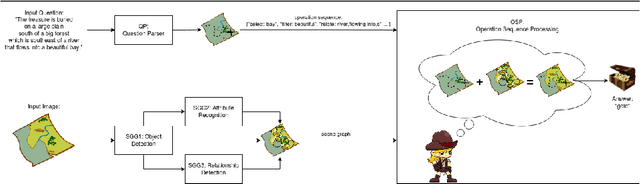
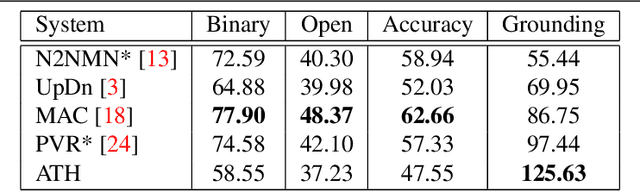
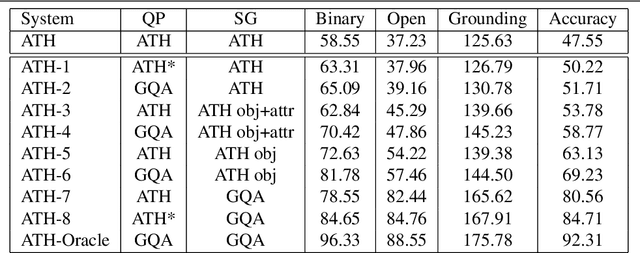
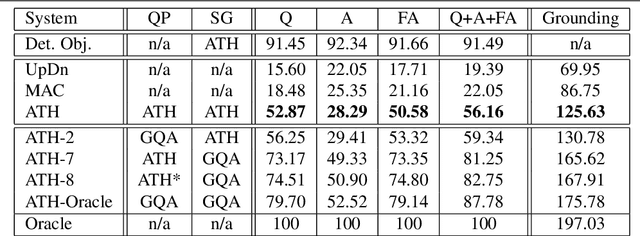
With the expressed goal of improving system transparency and visual grounding in the reasoning process in VQA, we present a modular system for the task of compositional VQA based on scene graphs. Our system is called "Adventurer's Treasure Hunt" (or ATH), named after an analogy we draw between our model's search procedure for an answer and an adventurer's search for treasure. We developed ATH with three characteristic features in mind: 1. By design, ATH allows us to explicitly quantify the impact of each of the sub-components on overall VQA performance, as well as their performance on their individual sub-task. 2. By modeling the search task after a treasure hunt, ATH inherently produces an explicit, visually grounded inference path for the processed question. 3. ATH is the first GQA-trained VQA system that dynamically extracts answers by querying the visual knowledge base directly, instead of selecting one from a specially learned classifier's output distribution over a pre-fixed answer vocabulary. We report detailed results on all components and their contributions to overall VQA performance on the GQA dataset and show that ATH achieves the highest visual grounding score among all examined systems.
Real or Virtual? Using Brain Activity Patterns to differentiate Attended Targets during Augmented Reality Scenarios
Jan 12, 2021
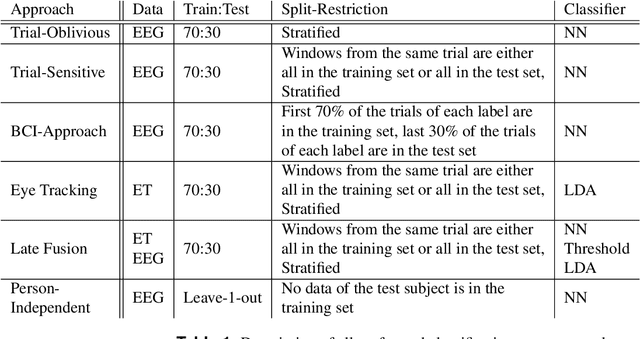


Augmented Reality is the fusion of virtual components and our real surroundings. The simultaneous visibility of generated and natural objects often requires users to direct their selective attention to a specific target that is either real or virtual. In this study, we investigated whether this target is real or virtual by using machine learning techniques to classify electroencephalographic (EEG) data collected in Augmented Reality scenarios. A shallow convolutional neural net classified 3 second data windows from 20 participants in a person-dependent manner with an average accuracy above 70\% if the testing data and training data came from different trials. Person-independent classification was possible above chance level for 6 out of 20 participants. Thus, the reliability of such a Brain-Computer Interface is high enough for it to be treated as a useful input mechanism for Augmented Reality applications.