 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Emotional Text-to-Speech Controllability with Natural Language Guidance through Contrastive Learning and Diffusion Models
Paper and Code
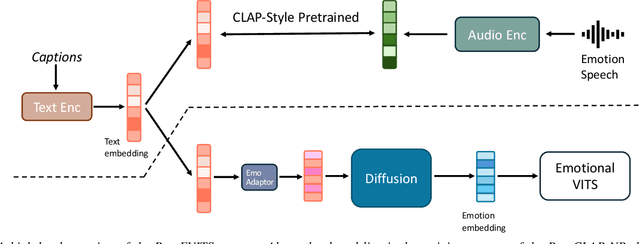
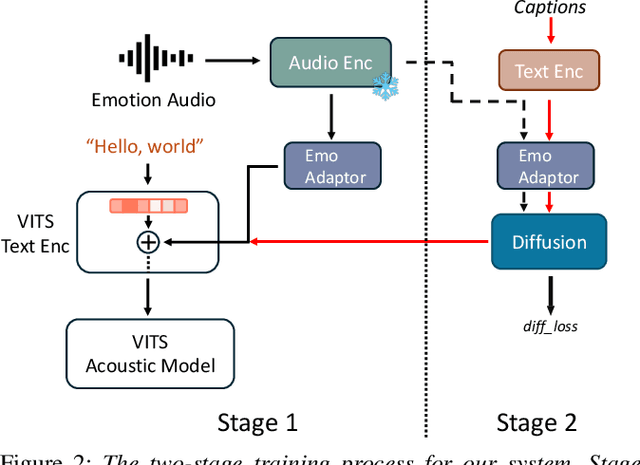

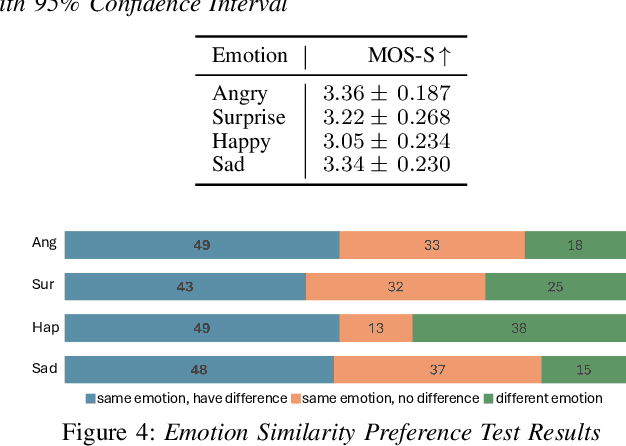
While current emotional text-to-speech (TTS) systems can generate highly intelligible emotional speech, achieving fine control over emotion rendering of the output speech still remains a significant challenge. In this paper, we introduce ParaEVITS, a novel emotional TTS framework that leverages the compositionality of natural language to enhance control over emotional rendering. By incorporating a text-audio encoder inspired by ParaCLAP, a contrastive language-audio pretraining (CLAP) model for computational paralinguistics, the diffusion model is trained to generate emotional embeddings based on textual emotional style descriptions. Our framework first trains on reference audio using the audio encoder, then fine-tunes a diffusion model to process textual inputs from ParaCLAP's text encoder. During inference, speech attributes such as pitch, jitter, and loudness are manipulated using only textual conditioning. Our experiments demonstrate that ParaEVITS effectively control emotion rendering without compromising speech quality. Speech demos are publicly available.