 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe devil is in the details: Enhancing Video Virtual Try-On via Keyframe-Driven Details Injection
Dec 23, 2025Although diffusion transformer (DiT)-based video virtual try-on (VVT) has made significant progress in synthesizing realistic videos, existing methods still struggle to capture fine-grained garment dynamics and preserve background integrity across video frames. They also incur high computational costs due to additional interaction modules introduced into DiTs, while the limited scale and quality of existing public datasets also restrict model generalization and effective training. To address these challenges, we propose a novel framework, KeyTailor, along with a large-scale, high-definition dataset, ViT-HD. The core idea of KeyTailor is a keyframe-driven details injection strategy, motivated by the fact that keyframes inherently contain both foreground dynamics and background consistency. Specifically, KeyTailor adopts an instruction-guided keyframe sampling strategy to filter informative frames from the input video. Subsequently,two tailored keyframe-driven modules, the garment details enhancement module and the collaborative background optimization module, are employed to distill garment dynamics into garment-related latents and to optimize the integrity of background latents, both guided by keyframes.These enriched details are then injected into standard DiT blocks together with pose, mask, and noise latents, enabling efficient and realistic try-on video synthesis. This design ensures consistency without explicitly modifying the DiT architecture, while simultaneously avoiding additional complexity. In addition, our dataset ViT-HD comprises 15, 070 high-quality video samples at a resolution of 810*1080, covering diverse garments. Extensive experiments demonstrate that KeyTailor outperforms state-of-the-art baselines in terms of garment fidelity and background integrity across both dynamic and static scenarios.
Reasoning to Edit: Hypothetical Instruction-Based Image Editing with Visual Reasoning
Jul 02, 2025Instruction-based image editing (IIE) has advanced rapidly with the success of diffusion models. However, existing efforts primarily focus on simple and explicit instructions to execute editing operations such as adding, deleting, moving, or swapping objects. They struggle to handle more complex implicit hypothetical instructions that require deeper reasoning to infer plausible visual changes and user intent. Additionally, current datasets provide limited support for training and evaluating reasoning-aware editing capabilities. Architecturally, these methods also lack mechanisms for fine-grained detail extraction that support such reasoning. To address these limitations, we propose Reason50K, a large-scale dataset specifically curated for training and evaluating hypothetical instruction reasoning image editing, along with ReasonBrain, a novel framework designed to reason over and execute implicit hypothetical instructions across diverse scenarios. Reason50K includes over 50K samples spanning four key reasoning scenarios: Physical, Temporal, Causal, and Story reasoning. ReasonBrain leverages Multimodal Large Language Models (MLLMs) for editing guidance generation and a diffusion model for image synthesis, incorporating a Fine-grained Reasoning Cue Extraction (FRCE) module to capture detailed visual and textual semantics essential for supporting instruction reasoning. To mitigate the semantic loss, we further introduce a Cross-Modal Enhancer (CME) that enables rich interactions between the fine-grained cues and MLLM-derived features. Extensive experiments demonstrate that ReasonBrain consistently outperforms state-of-the-art baselines on reasoning scenarios while exhibiting strong zero-shot generalization to conventional IIE tasks. Our dataset and code will be released publicly.
CasFT: Future Trend Modeling for Information Popularity Prediction with Dynamic Cues-Driven Diffusion Models
Sep 25, 2024



The rapid spread of diverse information on online social platforms has prompted both academia and industry to realize the importance of predicting content popularity, which could benefit a wide range of applications, such as recommendation systems and strategic decision-making. Recent works mainly focused on extracting spatiotemporal patterns inherent in the information diffusion process within a given observation period so as to predict its popularity over a future period of time. However, these works often overlook the future popularity trend, as future popularity could either increase exponentially or stagnate, introducing uncertainties to the prediction performance. Additionally, how to transfer the preceding-term dynamics learned from the observed diffusion process into future-term trends remains an unexplored challenge. Against this background, we propose CasFT, which leverages observed information Cascades and dynamic cues extracted via neural ODEs as conditions to guide the generation of Future popularity-increasing Trends through a diffusion model. These generated trends are then combined with the spatiotemporal patterns in the observed information cascade to make the final popularity prediction. Extensive experiments conducted on three real-world datasets demonstrate that CasFT significantly improves the prediction accuracy, compared to state-of-the-art approaches, yielding 2.2%-19.3% improvement across different datasets.
L1 Adaptive Resonance Ratio Control for Series Elastic Actuator with Guaranteed Transient Performance
May 25, 2023



To eliminate the static error, overshoot, and vibration of the series elastic actuator (SEA) position control, the resonance ratio control (RRC) algorithm is improved based on L1 adaptive control(L1AC)method. Based on the analysis of the factors affecting the control performance of SEA, the algorithm schema is proposed, the stability is proved, and the main control parameters are analyzed. The algorithm schema is further improved with gravity compensation, and the predicted error and reference error is reduced to guarantee transient performance. Finally, the effectiveness of the algorithm is validated by simulation and platform experiments. The simulation and experiment results show that the algorithm has good adaptability, can improve transient control performance, and can handle effectively the static error, overshoot, and vibration. In addition, when a link-side collision occurs, the algorithm automatically reduces the link speed and limits the motor current, thus protecting the humans and SEA itself, due to the low pass filter characterization of L1AC to disturbance.
AIM 2020 Challenge on Rendering Realistic Bokeh
Nov 10, 2020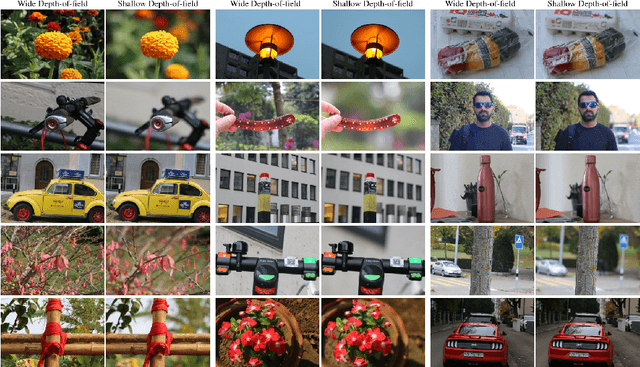


This paper reviews the second AIM realistic bokeh effect rendering challenge and provides the description of the proposed solutions and results. The participating teams were solving a real-world bokeh simulation problem, where the goal was to learn a realistic shallow focus technique using a large-scale EBB! bokeh dataset consisting of 5K shallow / wide depth-of-field image pairs captured using the Canon 7D DSLR camera. The participants had to render bokeh effect based on only one single frame without any additional data from other cameras or sensors. The target metric used in this challenge combined the runtime and the perceptual quality of the solutions measured in the user study. To ensure the efficiency of the submitted models, we measured their runtime on standard desktop CPUs as well as were running the models on smartphone GPUs. The proposed solutions significantly improved the baseline results, defining the state-of-the-art for practical bokeh effect rendering problem.