 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAD-UV: The 1st INTERSPEECH Mice Autism Detection via Ultrasound Vocalization Challenge
Jan 08, 2025


The Mice Autism Detection via Ultrasound Vocalization (MAD-UV) Challenge introduces the first INTERSPEECH challenge focused on detecting autism spectrum disorder (ASD) in mice through their vocalizations. Participants are tasked with developing models to automatically classify mice as either wild-type or ASD models based on recordings with a high sampling rate. Our baseline system employs a simple CNN-based classification using three different spectrogram features. Results demonstrate the feasibility of automated ASD detection, with the considered audible-range features achieving the best performance (UAR of 0.600 for segment-level and 0.625 for subject-level classification). This challenge bridges speech technology and biomedical research, offering opportunities to advance our understanding of ASD models through machine learning approaches. The findings suggest promising directions for vocalization analysis and highlight the potential value of audible and ultrasound vocalizations in ASD detection.
Deep Attention-based Representation Learning for Heart Sound Classification
Jan 13, 2021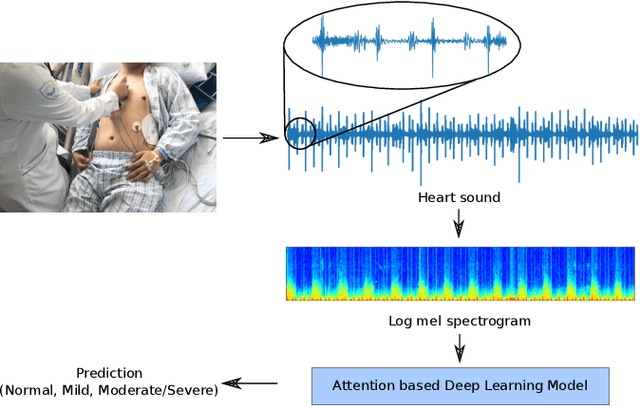
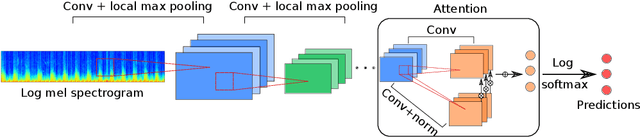
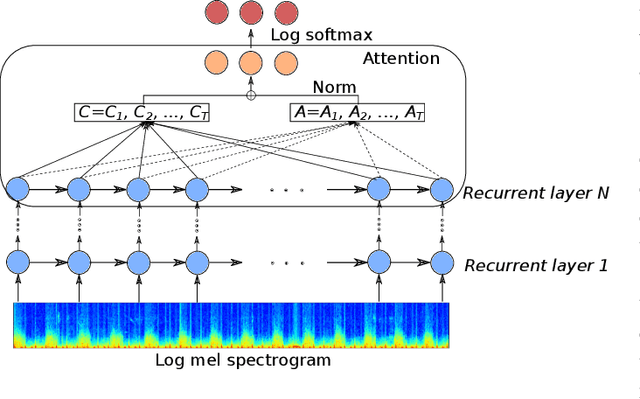
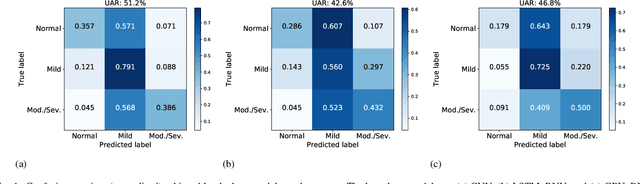
Cardiovascular diseases are the leading cause of deaths and severely threaten human health in daily life. On the one hand, there have been dramatically increasing demands from both the clinical practice and the smart home application for monitoring the heart status of subjects suffering from chronic cardiovascular diseases. On the other hand, experienced physicians who can perform an efficient auscultation are still lacking in terms of number. Automatic heart sound classification leveraging the power of advanced signal processing and machine learning technologies has shown encouraging results. Nevertheless, human hand-crafted features are expensive and time-consuming. To this end, we propose a novel deep representation learning method with an attention mechanism for heart sound classification. In this paradigm, high-level representations are learnt automatically from the recorded heart sound data. Particularly, a global attention pooling layer improves the performance of the learnt representations by estimating the contribution of each unit in feature maps. The Heart Sounds Shenzhen (HSS) corpus (170 subjects involved) is used to validate the proposed method. Experimental results validate that, our approach can achieve an unweighted average recall of 51.2% for classifying three categories of heart sounds, i. e., normal, mild, and moderate/severe annotated by cardiologists with the help of Echocardiography.
Recent Advances in Computer Audition for Diagnosing COVID-19: An Overview
Dec 08, 2020
Computer audition (CA) has been demonstrated to be efficient in healthcare domains for speech-affecting disorders (e.g., autism spectrum, depression, or Parkinson's disease) and body sound-affecting abnormalities (e. g., abnormal bowel sounds, heart murmurs, or snore sounds). Nevertheless, CA has been underestimated in the considered data-driven technologies for fighting the COVID-19 pandemic caused by the SARS-CoV-2 coronavirus. In this light, summarise the most recent advances in CA for COVID-19 speech and/or sound analysis. While the milestones achieved are encouraging, there are yet not any solid conclusions that can be made. This comes mostly, as data is still sparse, often not sufficiently validated and lacking in systematic comparison with related diseases that affect the respiratory system. In particular, CA-based methods cannot be a standalone screening tool for SARS-CoV-2. We hope this brief overview can provide a good guidance and attract more attention from a broader artificial intelligence community.
An Early Study on Intelligent Analysis of Speech under COVID-19: Severity, Sleep Quality, Fatigue, and Anxiety
May 14, 2020
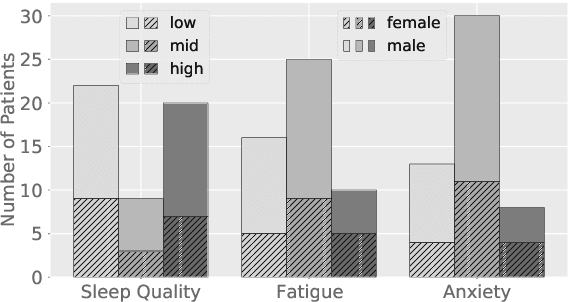

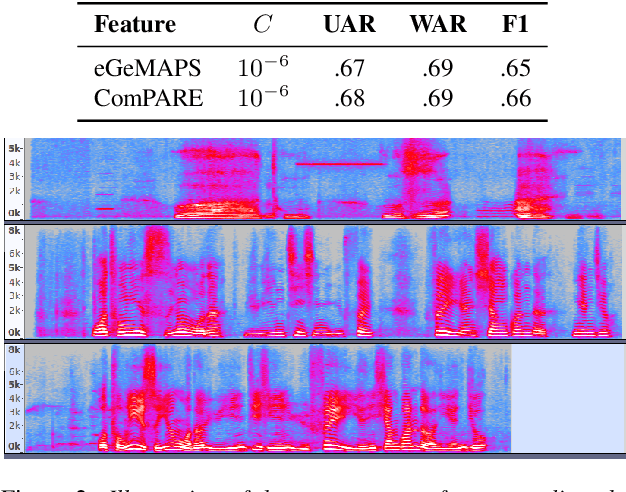
The COVID-19 outbreak was announced as a global pandemic by the World Health Organisation in March 2020 and has affected a growing number of people in the past few weeks. In this context, advanced artificial intelligence techniques are brought to the fore in responding to fight against and reduce the impact of this global health crisis. In this study, we focus on developing some potential use-cases of intelligent speech analysis for COVID-19 diagnosed patients. In particular, by analysing speech recordings from these patients, we construct audio-only-based models to automatically categorise the health state of patients from four aspects, including the severity of illness, sleep quality, fatigue, and anxiety. For this purpose, two established acoustic feature sets and support vector machines are utilised. Our experiments show that an average accuracy of .69 obtained estimating the severity of illness, which is derived from the number of days in hospitalisation. We hope that this study can foster an extremely fast, low-cost, and convenient way to automatically detect the COVID-19 disease.
deepSELF: An Open Source Deep Self End-to-End Learning Framework
May 11, 2020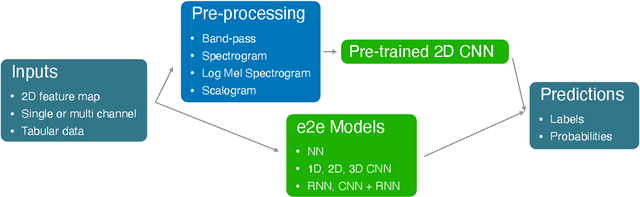

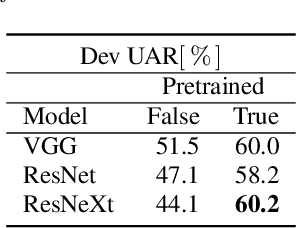
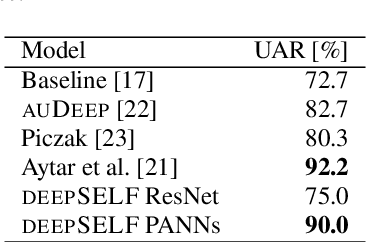
We introduce an open-source toolkit, i.e., the deep Self End-to-end Learning Framework (deepSELF), as a toolkit of deep self end-to-end learning framework for multi-modal signals. To the best of our knowledge, it is the first public toolkit assembling a series of state-of-the-art deep learning technologies. Highlights of the proposed deepSELF toolkit include: First, it can be used to analyse a variety of multi-modal signals, including images, audio, and single or multi-channel sensor data. Second, we provide multiple options for pre-processing, e.g., filtering, or spectrum image generation by Fourier or wavelet transformation. Third, plenty of topologies in terms of NN, 1D/2D/3D CNN, and RNN/LSTM/GRU can be customised and a series of pretrained 2D CNN models, e.g., AlexNet, VGGNet, ResNet can be used easily. Last but not least, above these features, deepSELF can be flexibly used not only as a single model but also as a fusion of such.