 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Self-supervised Learning: A Survey
Mar 02, 2022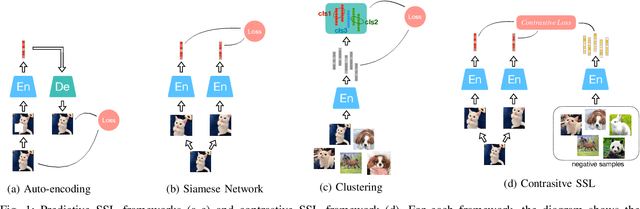
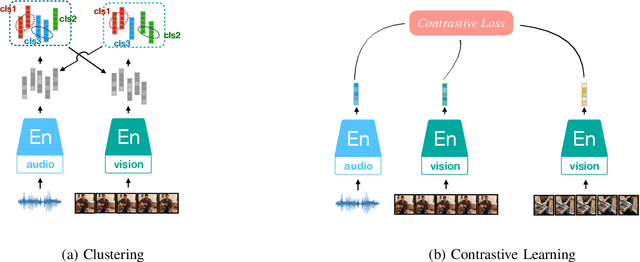
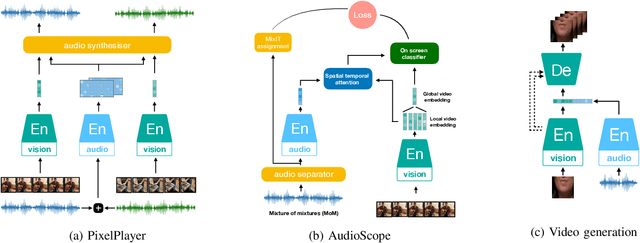
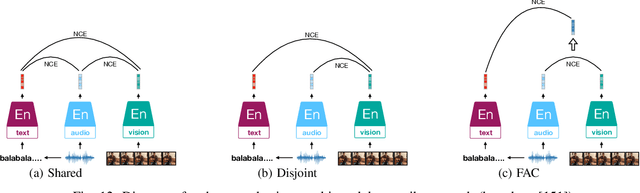
Inspired by the humans' cognitive ability to generalise knowledge and skills, Self-Supervised Learning (SSL) targets at discovering general representations from large-scale data without requiring human annotations, which is an expensive and time consuming task. Its success in the fields of computer vision and natural language processing have prompted its recent adoption into the field of audio and speech processing. Comprehensive reviews summarising the knowledge in audio SSL are currently missing. To fill this gap, in the present work, we provide an overview of the SSL methods used for audio and speech processing applications. Herein, we also summarise the empirical works that exploit the audio modality in multi-modal SSL frameworks, and the existing suitable benchmarks to evaluate the power of SSL in the computer audition domain. Finally, we discuss some open problems and point out the future directions on the development of audio SSL.