 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopITR: Combining Dual and Cross Encoder Architectures for Image-Text Retrieval
Paper and Code
Mar 10, 2022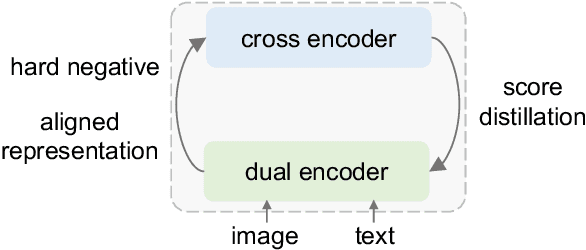
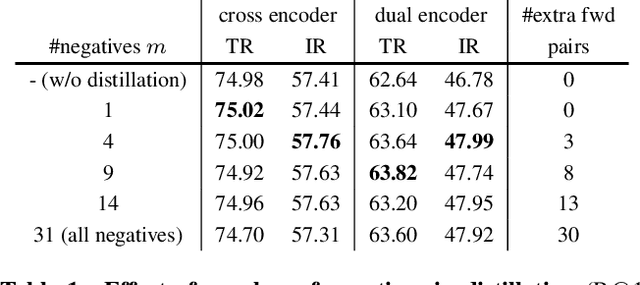

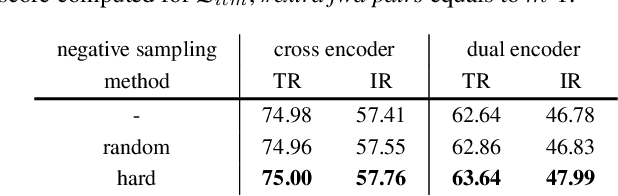
Dual encoders and cross encoders have been widely used for image-text retrieval. Between the two, the dual encoder encodes the image and text independently followed by a dot product, while the cross encoder jointly feeds image and text as the input and performs dense multi-modal fusion. These two architectures are typically modeled separately without interaction. In this work, we propose LoopITR, which combines them in the same network for joint learning. Specifically, we let the dual encoder provide hard negatives to the cross encoder, and use the more discriminative cross encoder to distill its predictions back to the dual encoder. Both steps are efficiently performed together in the same model. Our work centers on empirical analyses of this combined architecture, putting the main focus on the design of the distillation objective. Our experimental results highlight the benefits of training the two encoders in the same network, and demonstrate that distillation can be quite effective with just a few hard negative examples. Experiments on two standard datasets (Flickr30K and COCO) show our approach achieves state-of-the-art dual encoder performance when compared with approaches using a similar amount of data.