 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Shield: Defending Vision-Language Models Against Backdooring and Poisoning via Fine-grained Knowledge Alignment
Nov 23, 2024In recent years there has been enormous interest in vision-language models trained using self-supervised objectives. However, the use of large-scale datasets scraped from the web for training also makes these models vulnerable to potential security threats, such as backdooring and poisoning attacks. In this paper, we propose a method for mitigating such attacks on contrastively trained vision-language models. Our approach leverages external knowledge extracted from a language model to prevent models from learning correlations between image regions which lack strong alignment with external knowledge. We do this by imposing constraints to enforce that attention paid by the model to visual regions is proportional to the alignment of those regions with external knowledge. We conduct extensive experiments using a variety of recent backdooring and poisoning attacks on multiple datasets and architectures. Our results clearly demonstrate that our proposed approach is highly effective at defending against such attacks across multiple settings, while maintaining model utility and without requiring any changes at inference time
Enhanced Chart Understanding in Vision and Language Task via Cross-modal Pre-training on Plot Table Pairs
May 29, 2023
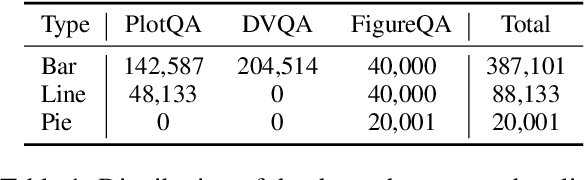
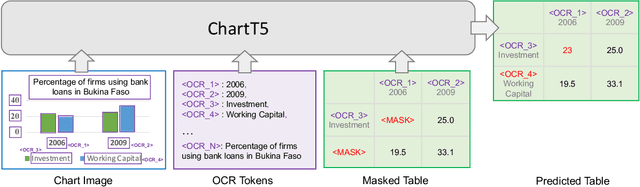
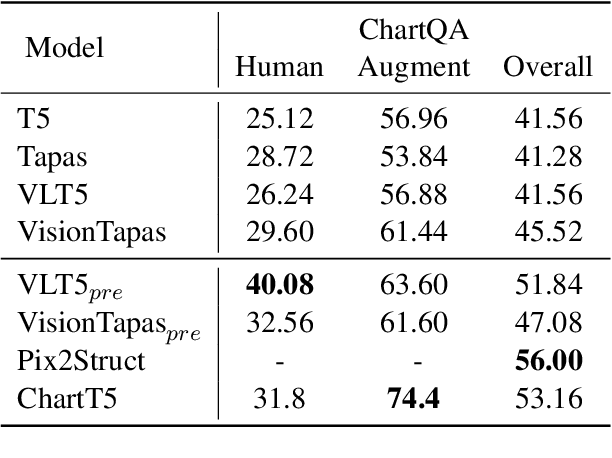
Building cross-model intelligence that can understand charts and communicate the salient information hidden behind them is an appealing challenge in the vision and language(V+L) community. The capability to uncover the underlined table data of chart figures is a critical key to automatic chart understanding. We introduce ChartT5, a V+L model that learns how to interpret table information from chart images via cross-modal pre-training on plot table pairs. Specifically, we propose two novel pre-training objectives: Masked Header Prediction (MHP) and Masked Value Prediction (MVP) to facilitate the model with different skills to interpret the table information. We have conducted extensive experiments on chart question answering and chart summarization to verify the effectiveness of the proposed pre-training strategies. In particular, on the ChartQA benchmark, our ChartT5 outperforms the state-of-the-art non-pretraining methods by over 8% performance gains.
Multimodal Event Graphs: Towards Event Centric Understanding of Multimodal World
Jun 14, 2022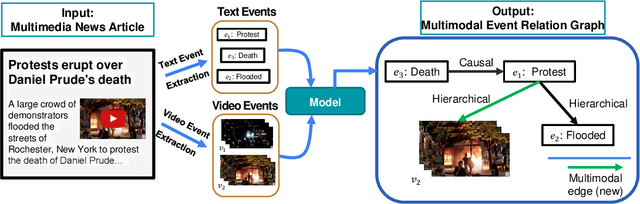
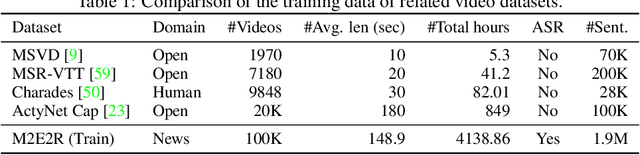
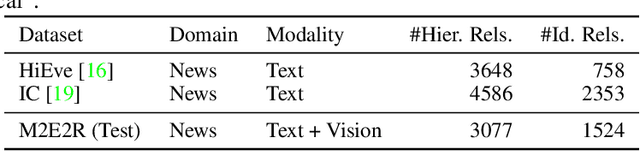

Understanding how events described or shown in multimedia content relate to one another is a critical component to developing robust artificially intelligent systems which can reason about real-world media. While much research has been devoted to event understanding in the text, image, and video domains, none have explored the complex relations that events experience across domains. For example, a news article may describe a `protest' event while a video shows an `arrest' event. Recognizing that the visual `arrest' event is a subevent of the broader `protest' event is a challenging, yet important problem that prior work has not explored. In this paper, we propose the novel task of MultiModal Event Event Relations to recognize such cross-modal event relations. We contribute a large-scale dataset consisting of 100k video-news article pairs, as well as a benchmark of densely annotated data. We also propose a weakly supervised multimodal method which integrates commonsense knowledge from an external knowledge base (KB) to predict rich multimodal event hierarchies. Experiments show that our model outperforms a number of competitive baselines on our proposed benchmark. We also perform a detailed analysis of our model's performance and suggest directions for future research.
Fine-Grained Visual Entailment
Mar 29, 2022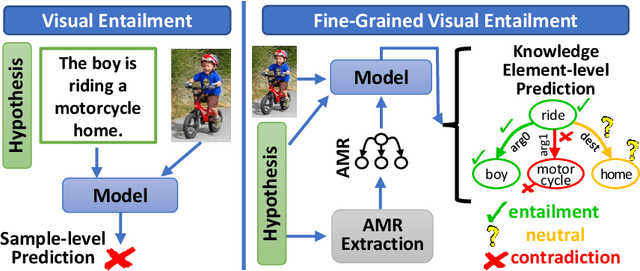
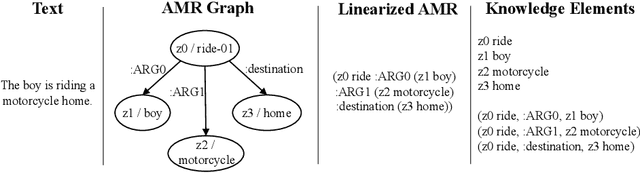
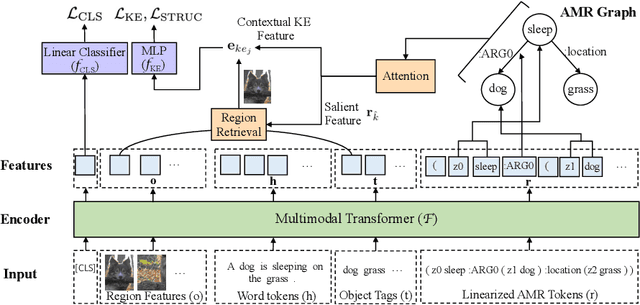
Visual entailment is a recently proposed multimodal reasoning task where the goal is to predict the logical relationship of a piece of text to an image. In this paper, we propose an extension of this task, where the goal is to predict the logical relationship of fine-grained knowledge elements within a piece of text to an image. Unlike prior work, our method is inherently explainable and makes logical predictions at different levels of granularity. Because we lack fine-grained labels to train our method, we propose a novel multi-instance learning approach which learns a fine-grained labeling using only sample-level supervision. We also impose novel semantic structural constraints which ensure that fine-grained predictions are internally semantically consistent. We evaluate our method on a new dataset of manually annotated knowledge elements and show that our method achieves 68.18\% accuracy at this challenging task while significantly outperforming several strong baselines. Finally, we present extensive qualitative results illustrating our method's predictions and the visual evidence our method relied on. Our code and annotated dataset can be found here: https://github.com/SkrighYZ/FGVE.
Joint Multimedia Event Extraction from Video and Article
Sep 27, 2021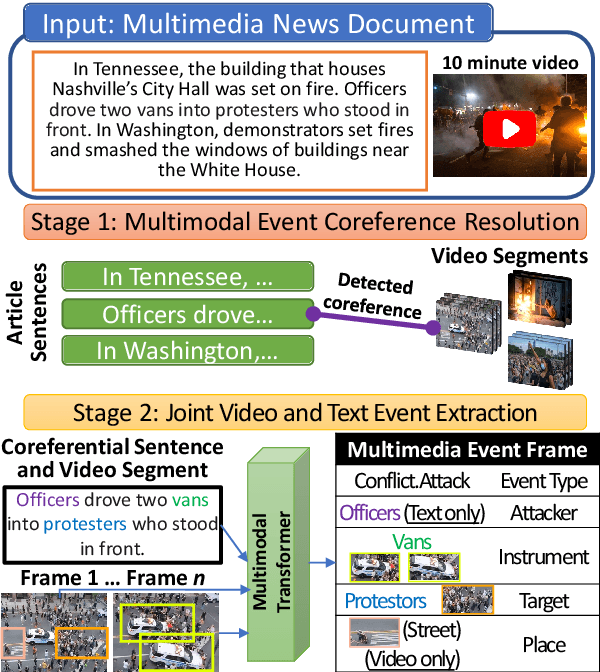
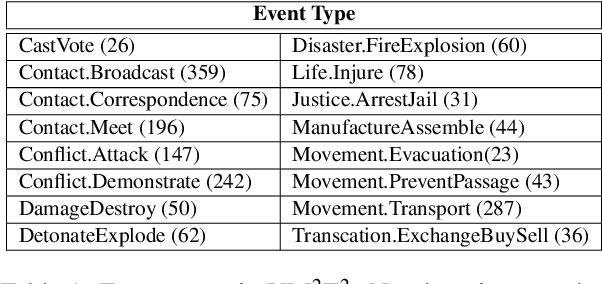


Visual and textual modalities contribute complementary information about events described in multimedia documents. Videos contain rich dynamics and detailed unfoldings of events, while text describes more high-level and abstract concepts. However, existing event extraction methods either do not handle video or solely target video while ignoring other modalities. In contrast, we propose the first approach to jointly extract events from video and text articles. We introduce the new task of Video MultiMedia Event Extraction (Video M2E2) and propose two novel components to build the first system towards this task. First, we propose the first self-supervised multimodal event coreference model that can determine coreference between video events and text events without any manually annotated pairs. Second, we introduce the first multimodal transformer which extracts structured event information jointly from both videos and text documents. We also construct and will publicly release a new benchmark of video-article pairs, consisting of 860 video-article pairs with extensive annotations for evaluating methods on this task. Our experimental results demonstrate the effectiveness of our proposed method on our new benchmark dataset. We achieve 6.0% and 5.8% absolute F-score gain on multimodal event coreference resolution and multimedia event extraction.
Learning to Transfer Visual Effects from Videos to Images
Dec 17, 2020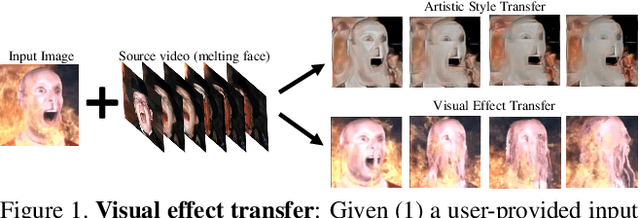
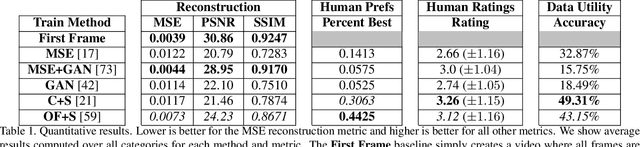
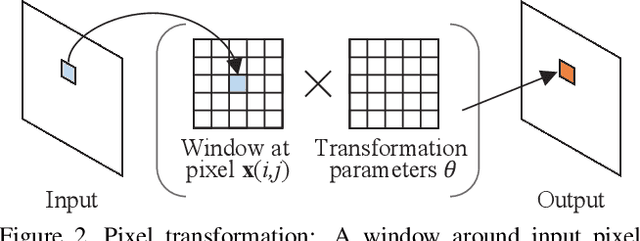

We study the problem of animating images by transferring spatio-temporal visual effects (such as melting) from a collection of videos. We tackle two primary challenges in visual effect transfer: 1) how to capture the effect we wish to distill; and 2) how to ensure that only the effect, rather than content or artistic style, is transferred from the source videos to the input image. To address the first challenge, we evaluate five loss functions; the most promising one encourages the generated animations to have similar optical flow and texture motions as the source videos. To address the second challenge, we only allow our model to move existing image pixels from the previous frame, rather than predicting unconstrained pixel values. This forces any visual effects to occur using the input image's pixels, preventing unwanted artistic style or content from the source video from appearing in the output. We evaluate our method in objective and subjective settings, and show interesting qualitative results which demonstrate objects undergoing atypical transformations, such as making a face melt or a deer bloom.
Preserving Semantic Neighborhoods for Robust Cross-modal Retrieval
Jul 16, 2020
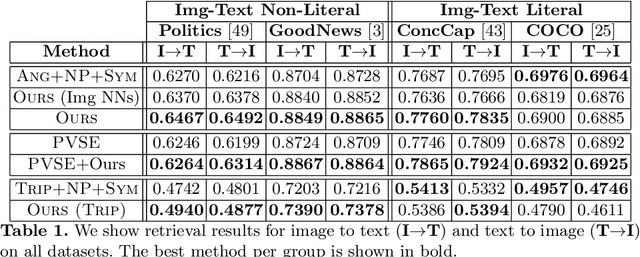
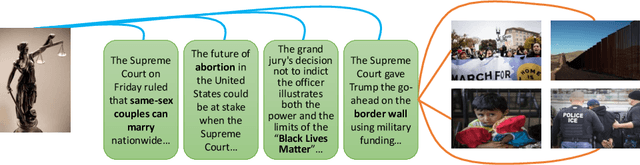

The abundance of multimodal data (e.g. social media posts) has inspired interest in cross-modal retrieval methods. Popular approaches rely on a variety of metric learning losses, which prescribe what the proximity of image and text should be, in the learned space. However, most prior methods have focused on the case where image and text convey redundant information; in contrast, real-world image-text pairs convey complementary information with little overlap. Further, images in news articles and media portray topics in a visually diverse fashion; thus, we need to take special care to ensure a meaningful image representation. We propose novel within-modality losses which encourage semantic coherency in both the text and image subspaces, which does not necessarily align with visual coherency. Our method ensures that not only are paired images and texts close, but the expected image-image and text-text relationships are also observed. Our approach improves the results of cross-modal retrieval on four datasets compared to five baselines.
Predicting the Politics of an Image Using Webly Supervised Data
Oct 31, 2019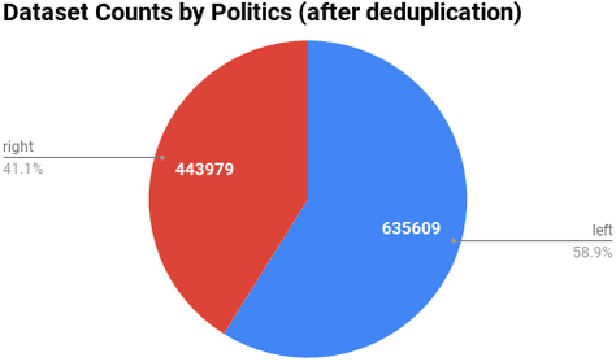



The news media shape public opinion, and often, the visual bias they contain is evident for human observers. This bias can be inferred from how different media sources portray different subjects or topics. In this paper, we model visual political bias in contemporary media sources at scale, using webly supervised data. We collect a dataset of over one million unique images and associated news articles from left- and right-leaning news sources, and develop a method to predict the image's political leaning. This problem is particularly challenging because of the enormous intra-class visual and semantic diversity of our data. We propose a two-stage method to tackle this problem. In the first stage, the model is forced to learn relevant visual concepts that, when joined with document embeddings computed from articles paired with the images, enable the model to predict bias. In the second stage, we remove the requirement of the text domain and train a visual classifier from the features of the former model. We show this two-stage approach facilitates learning and outperforms several strong baselines. We also present extensive qualitative results demonstrating the nuances of the data.
Artistic Object Recognition by Unsupervised Style Adaptation
Dec 28, 2018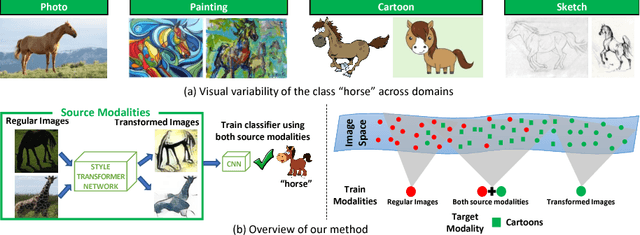
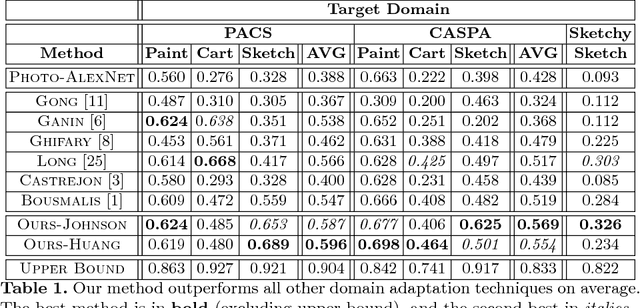
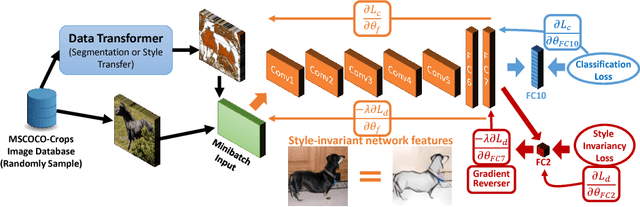
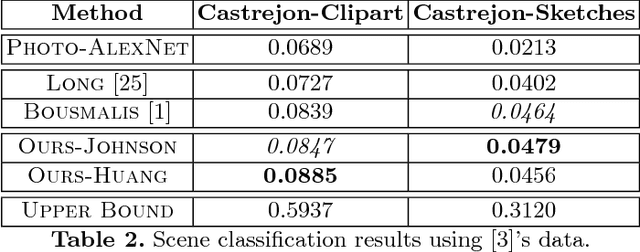
Computer vision systems currently lack the ability to reliably recognize artistically rendered objects, especially when such data is limited. In this paper, we propose a method for recognizing objects in artistic modalities (such as paintings, cartoons, or sketches), without requiring any labeled data from those modalities. Our method explicitly accounts for stylistic domain shifts between and within domains. To do so, we introduce a complementary training modality constructed to be similar in artistic style to the target domain, and enforce that the network learns features that are invariant between the two training modalities. We show how such artificial labeled source domains can be generated automatically through the use of style transfer techniques, using diverse target images to represent the style in the target domain. Unlike existing methods which require a large amount of unlabeled target data, our method can work with as few as ten unlabeled images. We evaluate it on a number of cross-domain object and scene classification tasks and on a new dataset we release. Our experiments show that our approach, though conceptually simple, significantly improves the accuracy that existing domain adaptation techniques obtain for artistic object recognition.
Persuasive Faces: Generating Faces in Advertisements
Jul 25, 2018
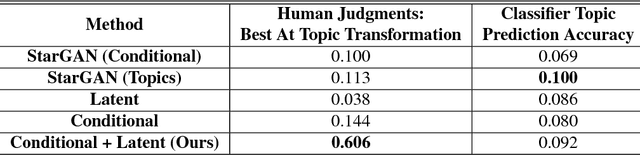

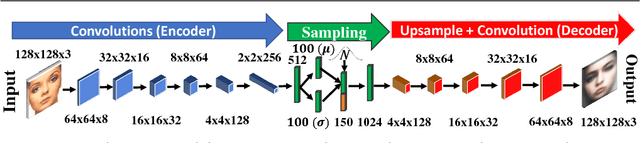
In this paper, we examine the visual variability of objects across different ad categories, i.e. what causes an advertisement to be visually persuasive. We focus on modeling and generating faces which appear to come from different types of ads. For example, if faces in beauty ads tend to be women wearing lipstick, a generative model should portray this distinct visual appearance. Training generative models which capture such category-specific differences is challenging because of the highly diverse appearance of faces in ads and the relatively limited amount of available training data. To address these problems, we propose a conditional variational autoencoder which makes use of predicted semantic attributes and facial expressions as a supervisory signal when training. We show how our model can be used to produce visually distinct faces which appear to be from a fixed ad topic category. Our human studies and quantitative and qualitative experiments confirm that our method greatly outperforms a variety of baselines, including two variations of a state-of-the-art generative adversarial network, for transforming faces to be more ad-category appropriate. Finally, we show preliminary generation results for other types of objects, conditioned on an ad topic.