 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Semantic Neighborhoods for Robust Cross-modal Retrieval
Paper and Code
Jul 16, 2020
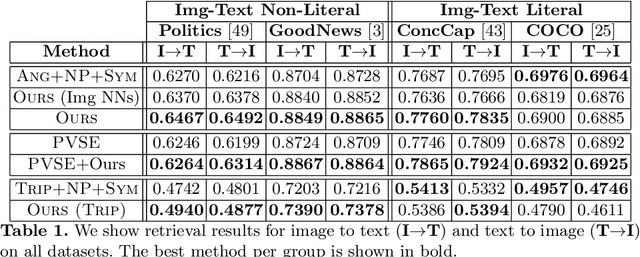
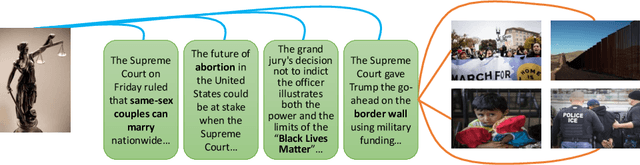

The abundance of multimodal data (e.g. social media posts) has inspired interest in cross-modal retrieval methods. Popular approaches rely on a variety of metric learning losses, which prescribe what the proximity of image and text should be, in the learned space. However, most prior methods have focused on the case where image and text convey redundant information; in contrast, real-world image-text pairs convey complementary information with little overlap. Further, images in news articles and media portray topics in a visually diverse fashion; thus, we need to take special care to ensure a meaningful image representation. We propose novel within-modality losses which encourage semantic coherency in both the text and image subspaces, which does not necessarily align with visual coherency. Our method ensures that not only are paired images and texts close, but the expected image-image and text-text relationships are also observed. Our approach improves the results of cross-modal retrieval on four datasets compared to five baselines.